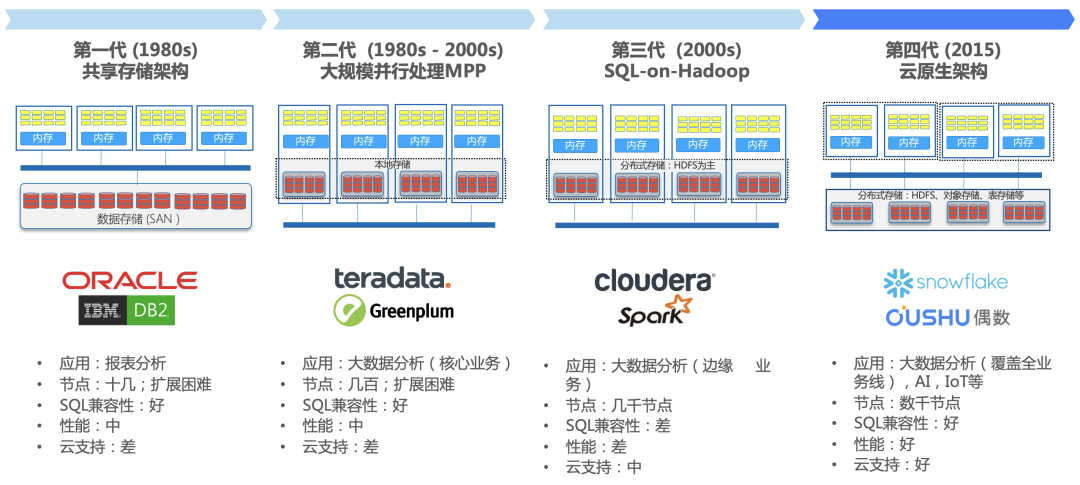
随着互联网技术的不断发展,各行各业的数据处理量与日俱增,Hadoop 作为一项革命性的技术提供了处理海量数据的能力,随之而来的 Spark 又大大提升了 Hadoop 的计算能力,解决了 Hadoop 的性能问题,受到了大数据行业的热捧。但到了 2022 年,Spark 依然是大数据行业的最佳选择吗?
Hadoop 生态系统经过多年的发展,已经在世界范围内广泛的采用,许多企业已经搭建了基于 Hadoop 生态圈的大数据平台,并且尝试更加深入的应用,比如数据仓库迁入的尝试,作为分析型场景的主要组件 Hive 与 Spark 扮演了主要的角色。
Hadoop 上的 SQL 支持一开始是 Apache Hive,Hive 自带的计算引擎是面向磁盘的 MapReduce,受限于磁盘读/写性能和网络 I/O 性能的约束,在处理迭代计算、实时计算、交互式数据查询等方面并不高效,其主要适用场景是批处理模式。针对这一不足,Spark 将数据存储在内存中并基于内存进行计算是一个有效的解决途径。Spark 允许将中间输出和结果存储在内存中,节省了大量的磁盘 IO。并且使用 DAG 调度程序,查询优化程序和物理执行引擎,实现批量和流式数据的高性能。同时 Spark 自身的 DAG 执行引擎也支持数据在内存中的计算。
偶数科技研发的数据仓库 OushuDB, 主要依托云原生特性、计算存储分离架构、强事务特性、完整 SQL 标准支持、高性能并行执行能力等一系列底层技术的变革,从而实现高弹性、高性能、强扩展性、强兼容性等上层技术的变革,最终帮助企业有效应对大规模、强敏态、高时效、智能化的趋势。
这次我们将对 OushuDB 与 Spark 3.0 的性能做一次对比。
数据查询哪家强?
为了更直观的比较 Spark 与 OushuDB 的查询能力,我们用 TPC-H(商业智能计算测试)来对 OushuDB 和 Spark 进行测试,TPC-H 是美国交易处理效能委员会(TPC,Transaction Processing Performance Council) 组织制定的用来模拟决策支持类应用的一个测试集,目前在学术界和工业界普遍采用它来评价数据查询处理能力。
国际通用的数据库测试标准 TPC-H 包括 22 个查询(Q1~Q22),我们主要的评价指标是各个查询的响应时间,即从提交查询到结果返回所需时间,我们分别对两个平台进行单节点使用 Scale 为 100 的数据集进行测试。
测试环境
服务器配置
- CPU:2 颗 10 核 Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz,超线程 40
- 内存:256GB
- 硬盘:4*1000GB SSD
- 操作系统:CentOS 7.4
对比软件版本
- OushuDB 4.0
- Spark 3.0
数据库参数
Spark

OushuDB

注:为测试在同一资源水平上,并且更接近生产实际,core 与内存设置相同,分别是 16 core 与 1gb
表属性
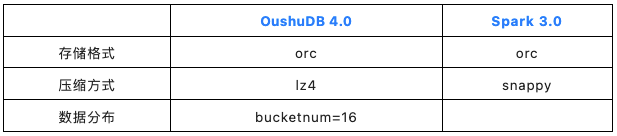
注:数据分布,OushuDB 可以表级设置及控制数据分布“桶数”,直接影响资源使用
数据生成方式
提前用 dbgen 生成 TPCH 测试用文本数据;OushuDB 采用外部表并行导入,并进行 Analyze。OushuDB 采用可写外部表将导入的数据写入指定的 HDFS 目录,供 Spark 导入数据。
Spark 建立外部表,指向 OushuDB 写出 HDFS 文件,将数据导入。
运行结果比较
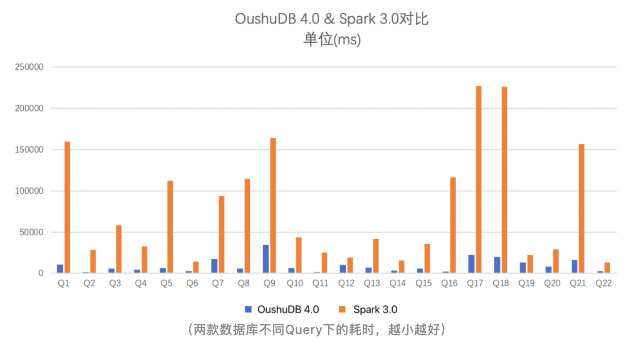
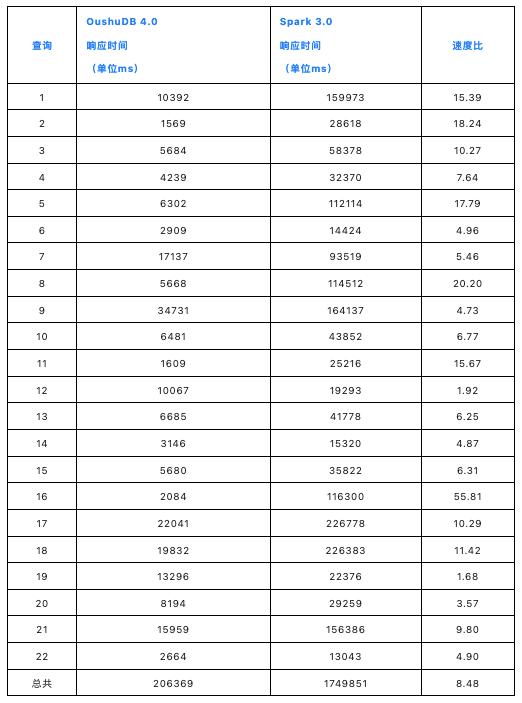
总结
Spark 新的自适应查询执行(AQE)框架只在某些场景提升了 Spark 性能,基于这次 TPC-H 测试由于新 SIMD 执行器的优势,OushuDB 全面性能超过 Spark 最大相差 55 倍,总体(22 查询个)性能 8 倍以上。在各行业实际应用场景进行大规模数据查询的过程中, OushuDB 的优势就相当明显了。
OushuDB 作为一款高性能云数据库,支持访问标准的 ORC 文件,并且具备高可扩展,遵循 ANSI-SQL 标准,具有极速执行器,提供 PB 级数据交互式查询能力,比传统数仓/MPP 快 5-10 倍,比 Hadoop SQL 引擎要快 5-30 倍。OushuDB 同时通过计算存储分离架构解决了传统数据仓库高成本、高门槛、难维护、难扩展的问题,可以让企业用户轻松构建核心数仓、数据集市、实时数仓以及湖仓一体数据平台,是当今的企业构建数据湖仓的不二选择。