OushuDB -- ODCP 课程学习笔记
OushuDB 简介
OushuDB 由国人自主研发,符合国家信创标准;通过计算存储分离架构解决了传统数据库高成本、高门槛、难维护、难扩展的问题。OushuDB 同时支持各大公有云和私有云。
Oushu Database(简称 OushuDB)是一款高性能云原生数据仓库,可以轻松用于构建核心数仓、数据集市、实时数仓、数据湖和湖仓一体数据平台。
OushuDB 通过计算存储分离架构解决了传统 MPP 数据仓库和 Hadoop 高成本、高门槛、难维护、难拓展的问题。同时支持各大公有云和私有云。另外,OushuDB 由国人自主研发、符合信创标准,已在金融、电信、工业、能源、互联网等各个行业得到广泛的应用,偶数科技已经服务大型金融、电信、政府、能源等众多领域的全球客户,其中包括建设银行、中国移动、中国联通、国家电网、南方电网、海尔等诸多世界 500 强企业,以及 VMware 等海外软件巨头。
新一代云数据仓库,融合了 MPP 和 Hadoop 的两者的优点,并且解决了两者的缺点。在兼容性和性能等方面表现的很优秀。OushuDB 以偶数主导开源的 Apache HAWQ 为基础,从设计之初就定位在新一代云数据仓库。OushuDB 的新一代 SIMD 执行器比传统 MPP 要快 5-10 倍,比一般的 SQL-on-Hadoop 要快 20 倍左右。OushuDB 支持 Update/Delete 和混合工作负载,实现了自己的存储,突破了 HDFS 的瓶颈。在可扩展性方面,因为采取了存储与计算分离的架构,可以扩展到上万节点,并且可以原生适应云计算的弹性需求。从而可以彻底满足 AI 和云时代的海量数据存储和分析的需求。
OushuDB 和 Apache HAWQ 的重要不同
- 全新执行器,性能得到 5-10 倍提升,3.x 新特性
- 支持 Update/Delete
- 支持索引,加速点查询
- 支持分布式表存储 Magma,支持混合工作负载
- 支持对象存储,简化了公有云上的存储部署
- 支持虚拟计算集群,实现了虚拟计算集群之间的资源隔离
- 支持 ORC 外部存储格式,结合新的执行器,外部存储的性能可以提升 10-50 倍
- 支持新一代可插拔存储框架,只需编写几个函数就可以添加一个外部数据源
- 支持 Master 节点 HA
![]()
OushuDB 产品特色
- 云原生:采用计算存储分离架构,利用云服务器、分布式存储,对数据基础设施的可扩展性进行深度优化,充分满足云端应用高度弹性、无限扩容的要求。支持腾讯云、阿里云、华为云、金山云、微软 Azure、AWS 等主流云平台。
- 高性能:面向 PB 级大数据的复杂查询,相比 MPP 和 SQL-on-Hadoop 快一个数量级。全新设计的执行器让性能提升 5~10 倍,显著降低批处理和即席查询所需的时间。
- 强兼容:具备完善的 SQL 标准和 ACID 特性,支持 HDFS 和多种对象存储的增删改查、以及偶数自研的 Magma 存储。兼容基于 Oracle,PostgreSQL,Greenplum 开发的数字应用,用户可以轻松实现不同数据基础设施的平稳迁移。
- 纯国产:OushuDB 由国内顶尖数据库内核研发团队自主开发,符合国家信创标准。偶数研发团队曾主导国际顶级的数据库开源项目。
- 应用广:OushuDB 已在金融、互联网、电信、政府、制造等行业的数百家头部企业得到广泛应用,助力各类企业完成数字化转型。
OushuDB 算存分离
OushuDB 是计算和存储分离的。它的数据是存储 Magma 或者是 HDFS 上。
高性能,高可用的分布式存储系统,在主节点上需要配置 MagmaObserver 他用来提供整个集群的 Magma 可用节点,
在各个从节点上会配置 MagmaNode。用来提供访问和存储 Magma 数据的服务,那数据还可以放在 HDFS 上。
OushuDB 现在支持多种存储格式:AO、ORC 和 Magma。AO 是按行存储的格式,而 ORC、Magma 是按行列存储的格式。
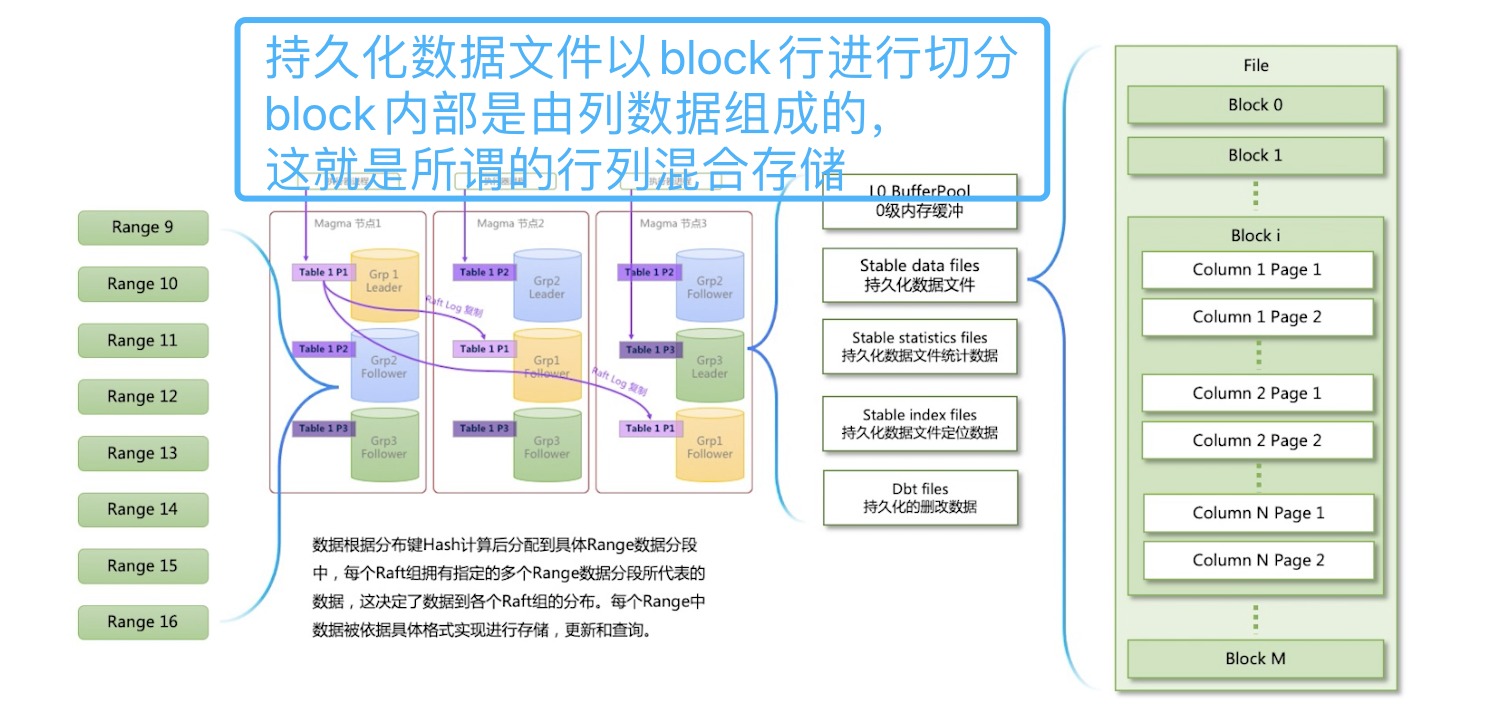
OushuDB 通过可插拔存储原生支持 HDFS,对象存储和自研分布式表存储 Magma。三大存储可以通过多虚拟存储集群的机制原生的接入 OushuDB,实现 IO 资源的物理隔离。
多虚拟存储集群技术(VSC)支持多路径,支持 IO 的负载均衡。来自于同一个 VSC 的用户表可以根据预定义的分布权重,负载均衡的打散到不同路径。创建表和使用表的过程对用户来说是完全透明的。
常用命令
启动/停止 OushuDB
source /usr/local/hawq/greenplum_path.sh # 设置OushuDB环境变量
hawq start cluster # 启动整个OushuDB集群
启动/停止 Magma
# 方式一 OushuDB4.0 集群起停带Magma服务 [只有hawq init|start|stop cluster命令可以带--with_magma选项]
hawq init cluster --with_magma # 启动OushuDB集群时,使用--with_magma选项,同时启动Magma服务, 3.X版本不支持。
# 方式二 Magma服务单独起停
magma start|stop|restart cluster
magma start|stop|restart node
创建一个新的数据库 test,并在新的数据库中创建一个表 foo。
psql -d postgres
create database test; # 创建数据库test
\c test # 连接进入test数据库
create table foo(id int, name varchar); # 创建表foo
\d # 显示当前数据库test中所有表
insert into foo values(1, 'hawq'),(2, 'hdfs');
select * from foo; # 从表foo中选择数据
explain analyze select count(*) from foo;
创建 schema
create schema myschema;
create table myschema.test(i int);
select * from myschema.test;
show search_path;
各种格式的表的建表语法
# 默认创建的是AO表
CREATE TABLE rank1 (id int, rank int, year smallint,gender char(1), count int );
# 和上面的创建的表一样,显式指定存储格式类型
CREATE TABLE rank2 (id int, rank int, year smallint,gender char(1), count int ) with (appendonly =true, orientation =row);
# 创建一个snappy压缩的AO表
CREATE TABLE rank3 (id int, rank int, year smallint,gender char(1), count int ) with (appendonly =true, orientation =row, compresstype = snappy);
# 创建一个snappy压缩的Parquet表,如果不指定压缩类型的话,默认不压缩。
CREATE TABLE rank3 (id int, rank int, year smallint,gender char(1), count int ) with (appendonly =true, orientation =parquet, compresstype = snappy);
# 创建一个不压缩的ORC表,如果不指定压缩类型的话,默认不压缩。
CREATE TABLE rank3 (id int, rank int, year smallint,gender char(1), count int ) with (appendonly =true, orientation =orc);
# 创建一个带压缩的ORC表,需指定压缩类型。
CREATE TABLE rank3 (id int, rank int, year smallint,gender char(1), count int ) with (appendonly =true, orientation =orc, compresstype = lz4);
# 创建一个压缩的magma表, magma 内部自动实现了压缩。
CREATE TABLE rank3 (id int, rank int, year smallint,gender char(1), count int ) format 'magmaap';
# 创建一个有primary key的magma表, magma 内部自动实现了压缩。
CREATE TABLE rank3 (id int, rank int, year smallint,gender char(1), count int,primary key(id) ) format 'magmaap';