OushuDB场景化实践系列(三):数据是如何存储的?
我们都知道,现在计算机的应用中,大多将数据存储到数据库中,但不知道大家是否有这样的一些疑问:
-
为什么要存到数据库中?
-
存在数据库的优势在哪里?
-
是否有必要,将数据存在数据库中?
这就要,先来了解一下文件是如何存储在计算机中了。
文件存储与数据库
我们知道,存储介质大概可以分为:
- 主存:存储量小,访问快
- 磁盘:存储量大,访问慢
自然,如果我们想存储大量的数据,存储在磁盘上的成本是我们可以接受的。问题的关键点就变成了:
设计一个高效的磁盘数据结构
从应用开发者的角度看,访问主存几乎是透明的,而对于磁盘的访问,是通过系统调用,感谢虚拟机内存机制的存在,让我们不用手动管理偏移量,我们只要指定目标文件内的相对偏移量,就可以从磁盘上的形式,解析成适合主存的形式。
我们需要设计出一种易于构造、修改和解析的文件格式。构建这样的一种文件结构,就像在内存模型的语言中构建数据结构。和我们熟知的 C 语言、Java 一样,我们期望它能自动处理好内存分配、垃圾收集和碎片的问题,让我们更聚焦在数据的使用、分析上,而不是要考虑是否有连续的内存段、内存释放后有什么影响等问题上。
很简单的一个问题:数据在计算机中,是以什么形式存储的?当然是二进制编码啦!
-
将数据变为二进制的这个过程,叫做序列化。
-
相反,将二进制变为原本的数据,叫做反序列化。
所以,为了数据的高效存储,我们需要将其编码成一种紧凑的、方便进行序列化和反序列化的格式。
而在数据记录成页之前,我们需要知道一个非常关键的问题:以什么样的结构存储数据?
- 如何以二进制的形式表示键、数据记录?
- 如何将多个值组成更复杂的结构?
- 如何实现可变长度的数据类型和数组?
数据类型
键和值,有很多类型,并且可以用二进制形式表示。(不记得的如何用二进制表示数据的童鞋,建议回顾一下计算机组成相关内容)
- 大多数的数值类型,用固定大小的值表示
- 多字节数值,需要在编解码时,使用相同的字节序
数据记录,由原始数据类型,及它们的组合构成。
- 数值
- 字符串
- 布尔值
数值类型
不同的数值类型,可能大小不同(一个字节 byte,是 8 比特位):
- 短整型:2byte = 16 位
- 整型:4byte = 32 位
- 长整型:8byte = 64 位
浮点数,也就是小数,由符号、小数、指数这三部分构成。(类似科学计数法的表示方法,一般使用的是 IEEE 二进制浮点算术标准)。
大多数语言中,都在标准库内置了编码和解码浮点数的方法。
下面,我们将学习一下偶数 DB 中,支持的数值类型,以及相关的细节问题。
整数:smallint、integer、bigint
| 名字 | 存储长度 | 描述 | 范围 |
|---|---|---|---|
| smallint | 2 字节 = 16 位 | 小范围整数 | -2^15 ~ 2^15-1 (有一位是符号位) -32768 到 32767 |
| integer | 4 字节 = 32 位 | 常用的整数 | -2^31 ~ 2^31-1 -2147483648 到 +2147483647 |
| bigint | 8 字节 = 64 位 | 大范围的整数 | -2^63 ~ 2^63-1 -9223372036854775808 到 +9223372036854775807 |
bigint 类型,依赖于编译器,是否支持 8 字节整数,所以不一定能在所有平台上使用。如果不支持,bigint 类型将退化成和 integer 一样,但依旧占用存储的 8 字节。
除了上述的 3 种之外,int2、int4、int8 之类的,可也在数据库系统中使用。
浮点数:real、double precision
| 名字 | 存储长度 | 描述 | 范围 |
|---|---|---|---|
| real | 4 字节 = 32 位 | 可变精度,不精确 | 6 位十进制数字精度 |
| double precision | 8 字节 = 64 位 | 可变精度,不精确 | 15 位十进制数字精度 |
| decimal | 可变长 | 用户指定的精度,精确 | 小数点前 131072 位, 小数点后 16383 为 |
| numeric | 可变长 | 用户指定的精度,精确 | 小数点前 131072 位, 小数点后 16383 位 |
浮点数最广为诟病的问题,就是精度问题。不精确 == 以近似值存储,存入的数值和取出的数值,可能不一样。
所以,在要求精确计算的场景,比如货币金额,就需要使用任意精度的数值类型,并指定其精度,进行精确的存储和计算。
写法一:NUMERIC(精度(全部数据位的数目)precision,标度(小数部分的位数)scale)
比如 9.99 元,精度为 3,标度为 2。,小数点不占位,这是一个类型 Numeric(3,2)的数据。
写法二:Numeric(精度 precision) // 省略标度
小数点后为 0 时,标度可以直接省略。
写法三: Numeric // 不带精度,也不带标度
这样,是创建了一个,可以实现精度上限的任意精度、标度的数值。
总结:一般推荐在使用 Numeric 时,明确声明精度和标度,保证兼容性和一致性。
字符串和可变长数据
原始的数值类型,有固定的大小。构造复杂的值,类似于 C 语言中的结构体 struct。
将原始值,组合到结构体中,并使用固定长度的数组,或是使用指针志向其他的内存区域。
字符串、可变长的数据类型,可以序列化为:
长度 size + size 个字节
size 个字节,才是实际的数据。对于字符串来说,这样的形式被称为 UCSD 字符串,或是 Pascal 字符串(Pascal 本身也是一种编程语言,以其流行实现而命名)。
// 伪代码表示
String {
size uint_16
data byte[size]
}
在偶数 DB 中,支持以下的字符串类型
| 名字 | 长度限制 | 是否定长 | 备注 |
|---|---|---|---|
| character(n), char(n) | √ | √ | 不补空白 |
| character varying(n), varchar(n) | √ | × | 当存储的字符长度,小于定长时, 会使用空白对字符串进行补齐 |
| text | × | × | 无长度限制,可以存储任意长度的字符串 |
- varchar(N):长度可以变化,当你的长度小于 N 时,不会有 N 个存储空间,只有你的实际长度加一,加一是因为额外使用一位来保存的长度,这是在 N 小于 255 的前提下。
如果 N 大于 255,则将使用额外的两位来保存长度。
布尔值
这里也给大家区分几个类似的概念:
- 布尔值:可以用单个字节表示,true 编码为 1,false 编码为 0
- 枚举值:可以表示为整数,常常用于二进制格式、通信协议,表示重复多、基数少的值
- 标志:打包的布尔值和枚举值的组合,表示多个非互斥的布尔值参数,类似于子网掩码的作用。比如,表示值是定长还是变长的,是否存在溢出页。(不懂可跳过,不是重点)
对于布尔值,只有两个取值,一般只占一个位。如果要用一个完整的字节存储,8 个位,就太浪费。所以,我们常常将每 8 个布尔值,合成一批,每个布尔值只占一位。
在 OushuDB 中,布尔类型 boolean 的存储,也是只占用 1 字节。
真值的表示为:
- TRUE
- true
- 'true'
- '1'
- 'y'
- 't'
相应的,对于假可以使用:
- FALSE
- ‘no'
- '0'
- 'false'
- 'n'
- 'f'
日期类型
| 名字 | 存储空间 | 描述 | 范围 | |
|---|---|---|---|---|
| 日期 | date | 4 字节 = 32 位 | 只用户日期 | 4713 BC 至 5874897 AD |
| 时间 | time [(p)] [ without time zone ] | 8 字节 = 64 位 | 只用于一日内时间 | 00:00:00 至 24:00:00 |
| time [(p)] with time zone | 12 字节 | 带时区 | 00:00:00+1459 至 24:00:00-1459 | |
| 时间/ 日期 |
timestamp [( p )] [without time zone] | 8 字节 | 日期和时间(无时区) | 4713 BC 至 294276 AD |
| timestamp [( p )] with time zone | 8 字节 | 有时区 | 4713 BC 至 294276 AD |
面向列与面向行的数据库
表格大家都看过吧~~~
每一个格子,都是行和列的交集。
- 属于同一列的字段,通常具有相同的数据类型
- name 列,都是字符串类型的
- price 列,都是数值类型的
- 在逻辑上,属于同一条数据记录的值,构成一行
表的存储,可以
- 水平分区:将属于同一行的值存储在一起
- 垂直分区:同属于一列的值,存储在一起
面向行
磁盘之类的持久性存储介质中,数据通常是按块访问的,单个块可能包含某行中所有的记录数据。如果我们想要访问某个用户的所有信息,那么这样的布局就非常方便。
在需要按行访问数据的情况下,面向行的存储最有用。整行存储,可以提高空间局部性。
(空间局部性:如果访问一处存储,则其附近的其他存储区域,也会在不久的将来被访问)
适用场景:
- 数据记录由多个字段组成
- 某个键,作为唯一标识
- 经常按行记录进行读取,比如用户的信息
- 经常单独修改某个字段
但是,如果我们想要获取多个用户的单个信息,比如手机号,就会让开销更大,因为其他字段在访问该块的时候,也会被读入。这个时候,就适合使用面向列的存储方式。
面向列
同一列的值,被连续地存储在磁盘上。不同列的值,存储在不同的文件,或文件段中。在读取的时候,同一列的值,可以一次性地读取出来,而不是对整行进行读取后,再丢弃不要的列。
适用场景:
- 计算聚合的分析型工作负载,比如查找趋势、计算平均值等
对于不断增长数据集,复杂分析查询的需求,出现了很多面向列的文件格式:
- Apache Parquet
- Apache ORC
- RCFile
面向列的存储:
- Apache Kudu
- ClickHouse
行和列的区别,只是存储方式不同吗?
当然不是,这只是我们对查询所做的优化之一。
区别二:缓存利用率、计算效率
在现代化 CPU 上(不是我们上学的时候学的古董 CPU),向量化指令可以使单条 CPU 指令,一次处理多个数据点。所以在一次读取中,从同一列中读取多个值,可以显著提高缓存利用率,和计算效率。
区别三:提高压缩率
数字和数字在一起,字符串和字符串在一起,根据不同的类型使用不同的压缩方法,每种情况选择最有效的压缩方法。
在 OuShuDB 中,也提供了不同的压缩方式,我们在创建表的时候,可以指定压缩方式。
总结:在决定使用那种存储之前,我们需要知道我们的访问方式。
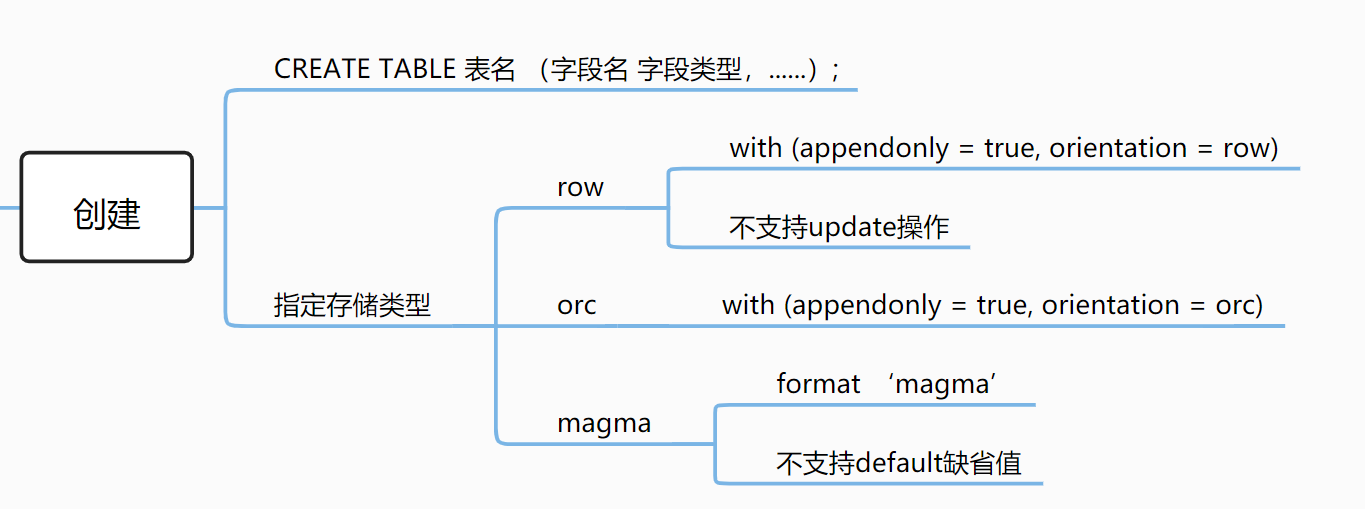
创建表时,指定存储方式
oushuDB 支持按行存储、按列存储、行列混合存储的方式。在创建表的时候,就可以进行指定,还可以同时指定压缩类型:
# 显式地指定row、orc
# 默认创建orc表(我测试时,默认创建的是orc)
CREATE TABLE goods (
id int
) with (appendonly = true, orientation = row); # 显式地指定存储格式:row、orc
# 指定压缩类型、AO表
# 如果不指定压缩类型的话,默认不压缩
CREATE TABLE goods (
id int
) with (appendonly = true, orientation = row, compresstype = snappy)
# 创建一个magma表
# magma 内部自动实现了压缩,自动实现了什么压缩?待确定。
CREATE TABLE goods(
id int
) format 'Magma';
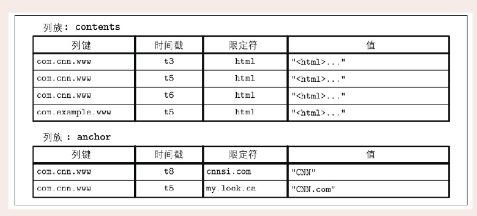
宽列式存储
列 ——> 列族 ,每个列族中,数据被逐行存储。
比如,一个 WebTable 表,存储这样的一些信息:
- 网页内容
- 属性
- 它们之间的关系
- 页面 url 标识
- ....
可以表示为一个嵌套的映射:

存储的时候:
在偶数 DB 中,支持多种存储格式:AO、ORC、Magma。
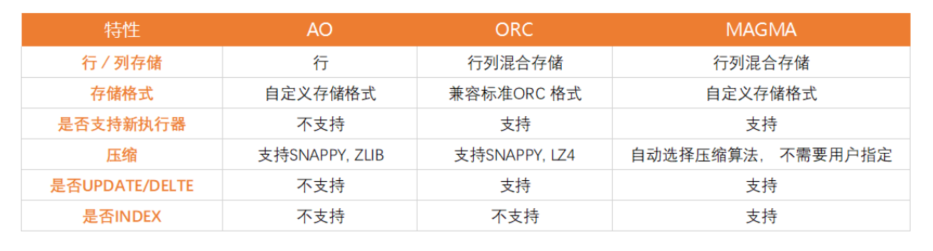
现在 AO 不支持,支持 row。
重构 goods 表
重新设计字段
要设计一张表,首先要考虑两个问题:
- 存储什么样的信息?
- 访问形式是什么样的?
考虑存储方式
goods 商品表,存储商品的信息,访问时,需要一条记录一条记录的访问,根据 id 或是 isbn 号,查询相应的商品价格,卖出或是删减库存等操作。所以,对于 goods 这样的表,我们应该按行存储、访问。
但是,在 OushuDB 中,按行存储还不支持数据的更新删除,所以我想,要不要用 magma 存储。
同样经过测试,magma 不支持默认设置,所以,我又试了 orc 存储,orc 目前支持的比较全面。
所以,最后我们选择 orc 来建表满足我们的需求。
重新设计字段
还记得 goods 表中的字段吗?我们重新设计一下吧~~~
| 字段 | 类型 | 是否必填 | 缺省值 | 说明 |
|---|---|---|---|---|
| title | varchar(255) | Y | 商品名称 | |
| purchase_price | numeric(10,2) | Y | 商品进价 | |
| sell_price | numeric(10,2) | Y | 商品售价 | |
| stock | integer | 0 | 商品库存 | |
| isbn | varchar(26) | 商品 ISBN 号 | ||
| unit | varchar(6) | 单位 | ||
| spec | varchar(20) | 规格 | ||
| brand | varchar(255) | 品牌 | ||
| supplier | varchar(255) | 生产厂商 | ||
| made_in | varchar(255) | 生产地 | ||
| create_time | timestamp | now() | 创建时间 | |
| update_time | timestamp | now() | 更新时间 | |
| delete_time | timestamp | now() | 删除时间 |
- 删除旧表
# 查看数据库内,现有的资源
# goods是我们之前创建的表,id_increment是我们创建的自增函数
# 同时还可以看到,goods的存储方式是orc,自增函数的存储方式是heap,也就是堆
happymarket=# \d
List of relations
Schema | Name | Type | Owner | Storage
--------+--------------+----------+---------+---------
public | goods | table | gpadmin | orc
public | id_increment | sequence | gpadmin | heap
(2 rows)
# 删除表
happymarket=# drop table goods;
DROP TABLE
# 再次查看,可以看到goods表已经删除了。
happymarket=# \d
List of relations
Schema | Name | Type | Owner | Storage
--------+--------------+----------+---------+---------
public | id_increment | sequence | gpadmin | heap
(1 row)
创建新表
我们现在来创建完整的 goods 表:
# 可复制直接执行,下一段给具体的注释
CREATE TABLE goods(
id int,
title varchar(255) NOT NUll,
purchase_price numeric(10,2) NOT NULL,
sell_price numeric(10,2) NOT NULL,
stock int DEFAULT 0,
isbn varchar(26),
unit varchar(6),
spec varchar(20),
brand varchar(255),
supplier varchar(255),
made_in varchar(255),
create_time timestamp DEFAULT now(),
update_time timestamp DEFAULT now(),
delete_time timestamp) with (appendonly = true, orientation = orc);
happymarket=#
CREATE TABLE goods( # 创建goods表
id int,
title varchar(255) NOT NUll, # NOT NULL 表示该字段不允许为空
purchase_price numeric(10,2) NOT NULL,
sell_price numeric(10,2) NOT NULL,
stock int DEFAULT 0,
isbn varchar(26),
unit varchar(6),
spec varchar(20),
brand varchar(255),
supplier varchar(255),
made_in varchar(255),
create_time timestamp DEFAULT now(), # 设置默认值为当前的时间
update_time timestamp DEFAULT now(),
delete_time timestamp
)with(appendonly = true, orientation = orc); # 设置存储格式为row
CREATE TABLE
happymarket=# \d
List of relations
Schema | Name | Type | Owner | Storage
--------+--------------+----------+---------+-------------
public | goods | table | gpadmin | append only
public | id_increment | sequence | gpadmin | heap
(3 rows)
导入一些数据
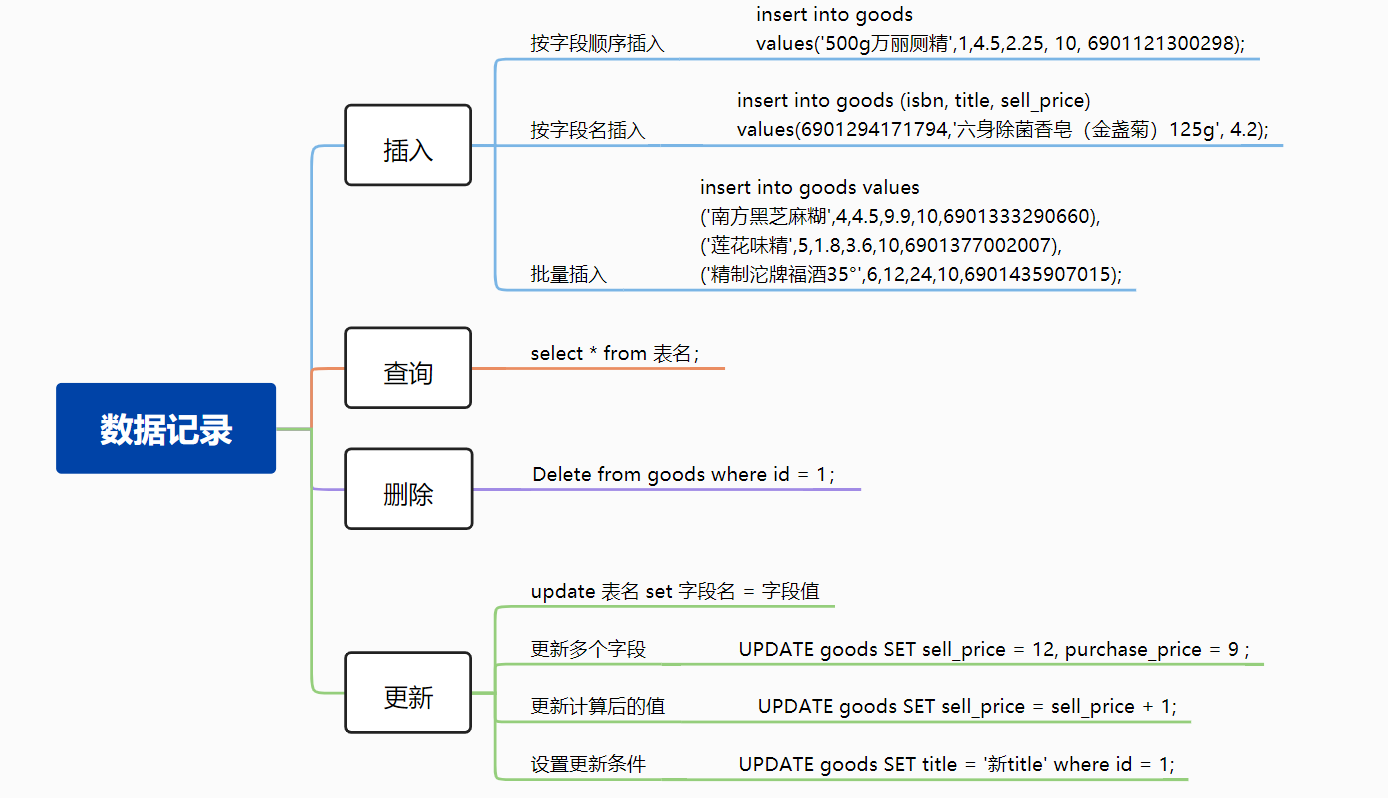
进了一些货(批量插入数据)
insert into goods (id, isbn, title, spec,unit,purchase_price, sell_price, brand, supplier, made_in)values
(1,6901121300298,'500g万丽厕精','500g','瓶',4.5,9,'万丽','广州市浪奇实业股份有限公司','广州'),
(2,6901294171206,'六神清凉爽肤沐浴露200ml','200ml','瓶',9.9,19.8,'六神','上海家化联合股份有限公司','上海'),
(3,6901294171213,'六神清凉爽肤沐浴露450ml','450ml','瓶',17.5,35,'六神','上海家化联合股份有限公司','上海'),
(4,6901294171381,'六神百合除菌香皂','125克','块',4.3,8.6,'六神','上海家化联合股份有限公司','上海'),
(5,6901294171794,'六神除菌香皂(金盏菊)125g','125g','块',4.2,8.4,'六神','上海家化联合股份有限公司','上海'),
(6,6901294172159,'六神冰凉超爽沐浴露200ml','200ml','瓶',10.5,21,'六神','上海家化联合股份有限公司','上海'),
(7,6901294177017,'六神清凉舒爽祛痱止痒花露水195ml','195ml','瓶',15,30,'六神','上海家化联合股份有限公司','上海'),
(8,6901294177024,'六神清凉舒爽祛痱止痒花露水95ml','95ml','瓶',10,20,'六神','上海家化联合股份有限公司','上海'),
(9,6901333290660,'南方黑芝麻糊','360克','袋',9.9,19.8,'南方黑芝麻','南方黑芝麻集团股份有限公司','广西'),
(10,6901377002007,'莲花味精','200克','包',3.6,7.2,'莲花','莲花健康产业集团股份有限公司','郑州'),
(11,6901377004001,'莲花味精','400克','包',7.2,14.4,'莲花','莲花健康产业集团股份有限公司','郑州'),
(12,6901377005008,'99%莲花味精','500g/500g','袋',10.9,21.8,'','莲花健康产业集团股份有限公司','河南'),
(13,6901435907015,'精制沱牌福酒35°','','瓶',4.5,9,'','舍得酒业股份有限公司','四川'),
(14,6901668053893,'奧利奧迷你原味小餅乾','55G','桶',5.5,11,'奧利奧','亿滋食品企业管理(上海)有限公司','江苏'),
(15,6901668053916,'奧利奧迷你巧克力餅乾','55G','桶',7,14,'奧利奧','亿滋食品企业管理(上海)有限公司','江苏'),
(16,6901668054012,'多种口味任选儿童宝宝休闲零食办公室小吃','106g','盒',23,46,'奥利奥','亿滋食品企业管理(上海)有限公司','江苏'),
(17,6901668054029,'奥利奥缤纷双果味夹心饼干树草莓+蓝莓味106g盒装','106g/106g','包',6.5,13,'奥利奥','亿滋食品企业管理(上海)有限公司','江苏'),
(18,6901668054050,'奥利奥130G夹心原味','130g','包',20,40,'奥利奥','亿滋食品企业管理(上海)有限公司','江苏'),
(19,6924097901160,'黑金刚大蘑头小蘑菇松脆小饼干(普通饼干~香浓巧克力)33298_45克','45g','盒',3.6,7.2,'黑金刚','天津市黑金刚食品有限公司','天津'),
(20,6924097901351,'黑金刚卡奇脆巧克力','4983_33克','块',1,2,'','天津市黑金刚食品有限公司','天津'),
(21,6924097901368,'黑金刚14g可可来代可可脂巧克力','*1/件','块',5.5,11,'','天津市黑金刚食品有限公司','天津'),
(22,6924254673381,'什锦水果罐头(岭南杂果)','700g/瓶','瓶',14.9,29.8,'','湛江市欢乐家食品有限公司','广东'),
(23,6924254673428,'欢乐家桔子罐头','700g','瓶',14,28,'','湛江市欢乐家食品有限公司','广东'),
(24,6924254673503,'糖水杨梅罐头','700g','瓶',13.5,27,'欢乐家','湛江市欢乐家食品有限公司','广东'),
(25,6924254673572,'糖水桃罐头(久宝桃)','700g','瓶',8.2,16.4,'欢乐家','湛江市欢乐家食品有限公司','广东'),
(26,6924534823277,'华发秀色12CM双层碗HF-056','','个',19.9,39.8,'','潮州市潮安区彩塘华丰不锈钢制品厂','福建'),
(27,6924583225206,'博远衣架','','包',20.9,41.8,'','西华县龙义和调味品厂','河南'),
(28,6924583291690,'方便胡辣汤','','包',21.9,43.8,'','西华县龙义和调味品厂','河南');
我们每种商品,进了 100 个,所以为每种商品,设置库存为 100
Update goods Set stock=100;
更新表中的数据的方法:
UPDATE goods SET title = '新title' where id = 1; # where条件下修改
UPDATE goods SET sell_price = sell_price + 1; # 执行计算修改
# 同时更新多个字段
UPDATE goods SET sell_price = 12, purchase_price = 9 where id = 1
ps: 在实际操作中,创建了三次表,不同的存储格式:
- row 不支持更新
- magma 不支持默认值、缺省值设置
记录商品卖出记录
有了商品,我们的超市可以开张了,当顾客购买了一件商品时,需要进行相关的记录,并执行减库存的操作。
对于相关的记录表,我们的需要大概如下:
- 不需要更改
- 需要经常查询,做分析
所以,我们依然选择 orc 存储。
字段设计
我们设计这个表的时候,是为了查询的时候能快捷方便,所以设计了按列存储。
但是,同样对于商品的信息,比如生产商,已经在 goods 表中存储过了,就形成了冗余存储。
- 如果不冗余存储,在查询的时候,goods 表也是按列存储的,按行查就很慢
- 如果冗余存储,每一条记录都会多存一些信息,积少成多
对此,为了满足高效查询的要求,就选择冗余存储吧。希望在按行存储时,能支持更新操作。
| 字段 | 类型 | 商品名称 |
|---|---|---|
| id | bigint | 记录 id,订单 id |
| isbn | varchar(26) | 商品 ISBN 号 |
| goods_id | int | 商品 id |
| title | varchar(255) | 商品名称 |
| purchase_price | numeric(10,2) | 商品进价 |
| sell_price | numeric(10,2) | 商品售价 |
| unit | varchar(6) | 单位 |
| spec | varchar(20) | 规格 |
| brand | varchar(255) | 品牌 |
| supplier | varchar(255) | 供应商 |
| made_in | varchar(255) | 产地 |
| sell_time | timestamp | 售出时间 |
创建表
CREATE TABLE orders(
id bigint,
goods_id int,
title varchar(255) NOT NUll,
purchase_price numeric(10,2) NOT NULL,
sell_price numeric(10,2) NOT NULL,
isbn varchar(26),
unit varchar(6),
spec varchar(20),
brand varchar(255),
supplier varchar(255),
made_in varchar(255),
sell_time timestamp DEFAULT now()) with (appendonly = true, orientation = orc);
# 查看现在,表的情况
happymarket=# \d
List of relations
Schema | Name | Type | Owner | Storage
--------+--------+-------+---------+---------
public | goods | table | gpadmin | orc
public | orders | table | gpadmin | orc
(2 rows)
happymarket=# \d+ orders
Orc Table "public.orders"
Column | Type | Modifiers | Storage | Description
----------------+-----------------------------+---------------+----------+-------------
id | bigint | | plain |
goods_id | integer | | plain |
title | character varying(255) | not null | extended |
purchase_price | numeric(10,2) | not null | main |
sell_price | numeric(10,2) | not null | main |
isbn | character varying(26) | | extended |
unit | character varying(6) | | extended |
spec | character varying(20) | | extended |
brand | character varying(255) | | extended |
supplier | character varying(255) | | extended |
made_in | character varying(255) | | extended |
sell_time | timestamp without time zone | default now() | plain |
Has OIDs: no
Options: appendonly=true, orientation=orc
Table Bucket Number: 8
Distributed randomly
happymarket=#
总结
现在,我们来总结一下,相关的命令: