OushuDB场景化实践系列(二):给超市进货
我们已经给超市起好名字了——happymarket。但巧妇难为无米之炊,超市没有商品怎么能行呢?
首先,我们需要给超市
进货。
为了给超市进货,我们需要有一个表单,来记录有哪些商品,以及商品的信息。这个表就叫做 goods 吧, 我们来想一想,有哪些商品信息是需要记录的?
1、确定记录哪些信息
- 一定要有商品的名字吧!——商品名称
- 找商品的时候,如果按名字找,挨个比较会非常麻烦!所以要给商品一个编号,这样按编号找就可以了——商品编号
- 商品价格一定要有呀!——商品进价、商品售价
- 那超市里,某个商品有多少库存,也需要记录啊!——商品库存
- 顾客来买商品的时候,我要如何快速知道多少钱呢?记得超市里的扫码枪吗?那个条形码,映射出的也是一个编号,是国家统一管理的,叫做 ISBN,所以我们还需要扫码枪和相应的编号——ISBN 号
- 还需要记录一些日期的信息,该条记录的——创建日期、更新日期
ps:一个商品,只有经过国家/国际的审查检验后,才会有 ISBN 号,没有的话就是三无产品了呦呵~~~
2、这些信息是什么类型的数据?
快过年了,年夜饭的时候,餐桌上美食被盛装在各种大小不一的盘子里。年年有鱼,需要一个长长的鱼盘子;东坡肘子需要一个中等的盘子,太小了装不下;红酒需要一个高脚杯;米饭需要一个饭碗......,如果你不小心打碎了一个,就碎碎平安了。
同样的,数据也需要不同的盘子装载,这个盘子叫做“数据类型”。不同的数据类型,作用不同,大小不同,处理方式不同。那么我们有哪些数据类型呢?
想一想,我们日常的信息都是什么样的?有的是数字,有的是文字,还有日历上的日期等等。
- 数值类型:记录数字,有整数、小数
- 字符类型:记录语言文字,有中文、英文、法文等
- 日期类型:记录日期
- 布尔类型:是或否
偶数 DB 的数据类型,和常用的数据库中的数据类型基本一致。我们先来认识几个:
- integer:整型,存储整数(负整数、零、正整数)
- numeric:分数、小数(正小数、零、负小数)
- text:字符串(单词、汉字、任何语言的文字形式)
- date:日期
好了,现在为我们需要存储的商品信息,确定一下其英文名字,和具体的类型吧
- 商品名称:一般是中文、英文,或是其他外文,所以是字符串 text
- 商品编号:一个整数,就是整型的 integer
- 商品进价:一个小数,numeric
- 商品售价:也是一个小数,numeric
- 商品库存:一个整数,integer
- ISBN 号:一个字符串,有字母和数字,所以是 text
- 创建日期:date
- 更新日期:date
在设计数据库字段时,我们一般用一个表格表示:
| 字段 | 类型 | 说明 |
|---|---|---|
| title | text | 商品名称 |
| id | integer | 商品 id、编号 |
| purchase_price | numeric | 商品进价 |
| sell_price | numeric | 商品售价 |
| stock | integer | 商品库存 |
| isbn | text | 商品 ISBN 号 |
| create_time | date | 创建时间 |
| update_time | date | 更新时间 |
3、创建商品表
现在我们已经好需要进哪些商品了,创建一张商品表,记录超市现有的商品和库存信息吧!
创建表的命令格式是:
CREATE TABLE 表名 (字段名 字段类型, 字段名 字段类型,......);
# 连接数据库
[gpadmin@localhost ~]$ psql -d happymarket
psql (8.2.15)
Type "help" for help.
happymarket=#
# 创建表
happymarket=# CREATE TABLE goods(title text, id integer, purhase_price numeric,sell_price numeric, stock integer, isbn text, create_time date, update_date date);
NOTICE: Using DECIMAL(10,0) for ORC DECIMAL instead
NOTICE: Using DECIMAL(10,0) for ORC DECIMAL instead
CREATE TABLE
# 查看创建表的信息
happymarket=# \d+ goods
Orc Table "public.goods"
Column | Type | Modifiers | Storage | Description
---------------+---------------+-----------+----------+-------------
title | text | | extended |
id | integer | | plain |
purhase_price | numeric(10,0) | | main |
sell_price | numeric(10,0) | | main |
stock | integer | | plain |
isbn | text | | extended |
create_time | date | | plain |
update_date | date | | plain |
Has OIDs: no
Options: appendonly=true, orientation=orc, compresstype=lz4
Table Bucket Number: 8
Distributed randomly
表是创建成功了,但有瑕疵呀,我的单词拼写错误了,进价是 purchase_price。还有,create_time 和 update_date 没有统一,最好改为 update_time。
所以,现在我们要修改一下字段名,使用 ALTER 命令。
# 修改purchase_price
happymarket=# ALTER TABLE goods RENAME COLUMN purhase_price TO purchase_price;
ALTER TABLE
# 修改update_time
happymarket=# ALTER TABLE goods RENAME COLUMN update_date TO update_time;
ALTER TABLE
happymarket=# \d+ goods
Orc Table "public.goods"
Column | Type | Modifiers | Storage | Description
----------------+---------------+-----------+----------+-------------
title | text | | extended |
id | integer | | plain |
purchase_price | numeric(10,0) | | main |
sell_price | numeric(10,0) | | main |
stock | integer | | plain |
isbn | text | | extended |
create_time | date | | plain |
update_time | date | | plain |
Has OIDs: no
Options: appendonly=true, orientation=orc, compresstype=lz4
Table Bucket Number: 8
Distributed randomly
重命名字段(列名)的方式:
ALTER TABLE 表名 RENAME COLUMN 原列名 TO 新列名
4、添加商品数据
现在,我们可以按照已经设定好的格式插入数据了。我们订购了一些日用品和零食:

现在我们就可以插入数据了。
列的格式大概是这样的:
| title | id | purchase_price | sell_price | stock | isbn | create_time | update_time |
|---|---|---|---|---|---|---|---|
| 500g 万丽厕精 | 1 | 4.5 | 2.25 | 10 | 6901121300298 | 2023.1.1 | 2023.1.1 |
ps:这里进价,就都按售价的一半算了,比较方便
我们先插入一条数据:
insert into 表名 values ( '字段值', '字段值',.... );
# 手动,插入一条数据
happymarket=# insert into goods values('500g万丽厕精',1,4.5,2.25, 10, 6901121300298);
INSERT 0 1
# 查看整张表的数据,*号表示所有字段
appymarket=# select * from goods;
title | id | purchase_price | sell_price | stock | isbn | creat
e_time | update_time
--------------+----+----------------+------------+-------+---------------+------
-------+-------------
500g万丽厕精 | 1 | 5 | 2 | 10 | 6901121300298 | 2023-
01-01 | 2023-01-01
(1 row)
ps:如果输入不了中文,需要设置:Applications——System Tools ——settings
然后找到一个小旗子 Region & Language,点开后在 input Source 内找到 China——Chinese(Intelligent Pinyin),添加后关闭。
在虚拟机内桌面的右上角,点击 en 切换成中文即可使用拼音输入中文了。
这样插入数据的命令,需要提前知道表中列的顺序,不是很方便。所以,还有另外一种方式,通过列出列名,并提供对应的数值来插入。
insert into 表名 (字段名,字段名,.....) values (相应的字段值,相应的字段值,......)
happymarket=# insert into goods (isbn, title, sell_price)
values(6901294171794,'六身除菌香皂(金盏菊)125g', 4.2);
INSERT 0 1
happymarket=# select * from goods;
title | id | purchase_price | sell_price | stock | isb
n | create_time | update_time
----------------------------+----+----------------+------------+-------+--------
-------+-------------+-------------
500g万丽厕精 | 1 | 5 | 2 | 10 | 6901121
300298 | 2023-01-01 | 2023-01-01
六身除菌香皂(金盏菊)125g | | | 4 | | 6901294
171794 | |
六身除菌香皂(金盏菊)125g | | | 4 | | 6901294
171794 | |
(3 rows)
你一定会问,这么多商品,要如何自动、批量地插入?
这个场景,和民房拆迁,迁入新楼房很类似。楼盘相当于数据库,居民相当于一条条数据,每家住户居民,想要居住的地方不同,根据财力能居住的大小也不同,即便是拆迁后一大批的住户居民需要入住新房,但是也要一个个的办理手续。
在数据库中插入数据也是一样,实际上都是一条一条插入的。但是,我们可以将这个过程变得自动化:
- 批量插入的命令语句
- 调用代码去扫描、写循环的逻辑插入
- ......
批量插入的命令语句,就是将数据行用逗号连接起来:
# 批量插入数据
happymarket=# insert into goods values
('南方黑芝麻糊',4,4.5,9.9,10,6901333290660,'2023.1.1','2023.1.2'),
('莲花味精',5,1.8,3.6,10,6901377002007,'2023.1.1','2023.1.2'),
('精制沱牌福酒35°',6,12,24,10,6901435907015,'2023.1.1','2023.1.2');
INSERT 0 3
# 查看
happymarket=# select * from goods;
title | id | purchase_price | sell_price | stock | isbn | create_time | update_time
----------------------------+----+----------------+------------+-------+---------------+-------------+-------------
500g万丽厕精 | 1 | 5 | 2 | 10 | 6901121300298 | 2023-01-01 | 2023-01-01
六身除菌香皂(金盏菊)125g | | | 4 | | 6901294171794 | |
六身除菌香皂(金盏菊)125g | | | 4 | | 6901294171794 | |
南方黑芝麻糊 | 4 | 5 | 10 | 10 | 6901333290660 | 2023-01-01 | 2023-01-02
莲花味精 | 5 | 2 | 4 | 10 | 6901377002007 | 2023-01-01 | 2023-01-02
精制沱牌福酒35° | 6 | 12 | 24 | 10 | 6901435907015 | 2023-01-01 | 2023-01-02
(6 rows)
5、缺少商品信息了
在进货的时候,我们发现,商品还有很多其他的信息和归类:
- 单位:是瓶装,还是盒装的,还是一包一包的
- 品牌:比如奥利奥、六神、小当家、盼盼
- 出厂商/制作商
- 生产地
实际走访会发现,我们会从进货商那边,拿到类似这样的表格:
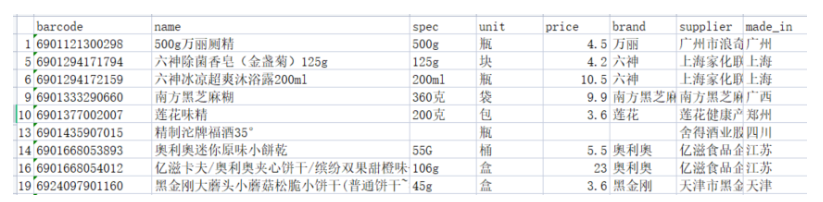
所以,我们也依次设计字段
| 字段 | 类型 | 说明 |
|---|---|---|
| unit | text | 单位 |
| spec | text | 规格 |
| brand | text | 品牌 |
| supplier | text | 生产厂商 |
| made_in | text | 生产地 |
所以,我们还要补充添加更多的字段,也就是增加列。按照我们现在的想法,命令语句大概是这样的:
ALTER TABLE 表名 ADD COLUMN 字段名 字段类型;
执行一下:
happymarket=# ALTER TABLE goods ADD COLUMN unit text;
ERROR: ADD COLUMN with no default value in append-only tables is not yet supported.
它竟然报错了!错误提示:增加的列,没有默认值。
默认值,我们也常常叫做缺省值,顾名思义,缺少省略插入时,默认填充的值。因为我们是增加的一个新字段,之前插入的数据都没有这个字段,我们要给它们填充一个默认值。
另一方面,我们也可以给已有的字段添加默认值/缺省值,这样在插入数据的时候,不用指定值也会填充默认值。
这样一来,就方便很多,比如:
-
日期类数据:自动填充为插入的时间
-
自增类 id:自动增长的编号,自动填充上一个值 +1
-
其他不是必须的:可以都默认为空
增加默认值/缺省值的方式有三种:
- 在创建时增加
- 在增加新字段时指定:ALTER TABLE 表名 ADD COLUMN 字段名 字段类型 DEFAULT 默认值;
- 单独改变某列的缺省值:ALTER TABLE 表名 ALTER COLUMN 字段名 SET DEFAULT 默认值;
现在我们实践后两种方式
# 增加新字段,并填充缺省值为空
happymarket=# ALTER TABLE goods ADD COLUMN unit text DEFAULT '';
NOTICE: Using a scale of zero for ORC DECIMAL
NOTICE: Using a scale of zero for ORC DECIMAL
ALTER TABLE
happymarket=# \d+ goods
Orc Table "public.goods"
Column | Type | Modifiers | Storage | Description
----------------+---------------+------------------+----------+-------------
title | text | | extended |
id | integer | | plain |
purchase_price | numeric(10,0) | | main |
sell_price | numeric(10,0) | | main |
stock | integer | | plain |
isbn | text | | extended |
create_time | date | | plain |
update_time | date | | plain |
unit | text | default ''::text | extended |
Has OIDs: no
Options: appendonly=true, orientation=orc, compresstype=lz4
Table Bucket Number: 8
Distributed randomly
# 给已有字段设置缺省值
happymarket=# ALTER TABLE goods ALTER COLUMN purchase_price SET DEFAULT 0;
ALTER TABLE
happymarket=# \d+ goods
Orc Table "public.goods"
Column | Type | Modifiers | Storage | Description
----------------+---------------+------------------+----------+-------------
title | text | | extended |
id | integer | | plain |
purchase_price | numeric(10,0) | default 0 | main |
sell_price | numeric(10,0) | | main |
stock | integer | | plain |
isbn | text | | extended |
create_time | date | | plain |
update_time | date | | plain |
unit | text | default ''::text | extended |
Has OIDs: no
Options: appendonly=true, orientation=orc, compresstype=lz4
Table Bucket Number: 8
Distributed randomly
# 增加新字段,并设置默认值
# 输入命令小技巧:对于输入过的命令,或是类似的命令,可以直接按键盘中的上下键找到,修改不同的部分,然后回车执行。
happymarket=# ALTER TABLE goods ADD COLUMN spec text DEFAULT '';
NOTICE: Using a scale of zero for ORC DECIMAL
NOTICE: Using a scale of zero for ORC DECIMAL
ALTER TABLE
happymarket=# ALTER TABLE goods ADD COLUMN brand text DEFAULT '';
NOTICE: Using a scale of zero for ORC DECIMAL
NOTICE: Using a scale of zero for ORC DECIMAL
ALTER TABLE
happymarket=# ALTER TABLE goods ADD COLUMN supplier text DEFAULT '';
NOTICE: Using a scale of zero for ORC DECIMAL
NOTICE: Using a scale of zero for ORC DECIMAL
ALTER TABLE
happymarket=# ALTER TABLE goods ADD COLUMN made_in text DEFAULT '';
NOTICE: Using a scale of zero for ORC DECIMAL
NOTICE: Using a scale of zero for ORC DECIMAL
ALTER TABLE
happymarket=# \d+ goods
Orc Table "public.goods"
Column | Type | Modifiers | Storage | Description
----------------+---------------+------------------+----------+-------------
title | text | | extended |
id | integer | | plain |
purchase_price | numeric(10,0) | default 0 | main |
sell_price | numeric(10,0) | | main |
stock | integer | | plain |
isbn | text | | extended |
create_time | date | | plain |
update_time | date | | plain |
unit | text | default ''::text | extended |
spec | text | default ''::text | extended |
brand | text | default ''::text | extended |
supplier | text | default ''::text | extended |
made_in | text | default ''::text | extended |
Has OIDs: no
Options: appendonly=true, orientation=orc, compresstype=lz4
Table Bucket Number: 8
Distributed randomly
现在,我们想一想,要如何给已有的字段 ID 设置自增,给日期设置默认当前的时间?
6、使用函数设置默认值
答案如标题。因为设置的值,不是默认值,所以需要函数去获取,或是进行一些操作。
日期类:缺省值设置为 now(),表示插入行的时刻
happymarket=# ALTER TABLE goods ALTER COLUMN create_time SET DEFAULT now();
ALTER TABLE
happymarket=# ALTER TABLE goods ALTER COLUMN update_time SET DEFAULT now();
ALTER TABLE
# 现在,我们新插入一条数据,测试一下
happymarket=# insert into goods values
('南方黑芝麻糊',4,4.5,9.9,10,6901333290660),
('莲花味精',5,1.8,3.6,10,6901377002007),
('精制沱牌福酒35°',6,12,24,10,6901435907015);
INSERT 0 3
happymarket=# select * from goods;
title | id | purchase_price | sell_price | stock | isbn | create_time | update_time | unit | spec | brand | supplier | made_in
----------------------------+----+----------------+------------+-------+---------------+-------------+-------------+------+------+-------+----------+---------
500g万丽厕精 | 1 | 5 | 2 | 10 | 6901121300298 | 2023-01-01 | 2023-01-01 | | | | |
六身除菌香皂(金盏菊)125g | | | 4 | | 6901294171794 | | | | | | |
六身除菌香皂(金盏菊)125g | | | 4 | | 6901294171794 | | | | | | |
南方黑芝麻糊 | 4 | 5 | 10 | 10 | 6901333290660 | 2023-01-01 | 2023-01-02 | | | | |
莲花味精 | 5 | 2 | 4 | 10 | 6901377002007 | 2023-01-01 | 2023-01-02 | | | | |
精制沱牌福酒35° | 6 | 12 | 24 | 10 | 6901435907015 | 2023-01-01 | 2023-01-02 | | | | |
南方黑芝麻糊 | 4 | 5 | 10 | 10 | 6901333290660 | 2023-01-01 | 2023-01-02 | | | | |
莲花味精 | 5 | 2 | 4 | 10 | 6901377002007 | 2023-01-01 | 2023-01-02 | | | | |
精制沱牌福酒35° | 6 | 12 | 24 | 10 | 6901435907015 | 2023-01-01 | 2023-01-02 | | | | |
南方黑芝麻糊 | 4 | 5 | 10 | 10 | 6901333290660 | 2023-01-02 | 2023-01-02 | | | | |
莲花味精 | 5 | 2 | 4 | 10 | 6901377002007 | 2023-01-02 | 2023-01-02 | | | | |
精制沱牌福酒35° | 6 | 12 | 24 | 10 | 6901435907015 | 2023-01-02 | 2023-01-02 | | | | |
(12 rows)
# 没有问题,最后插入的三条,我们没有写日期,也默认为日期了
自增 ID 如何实现?
一种直白的思路是,我们写个函数,每次执行插入的时候去调用一下就可以了。另一种方法,是在创建的时候内置。
- 写函数调用
创建函数:create sequence 函数名 increment by 1 minvalue 1 no maxvalue start with 1;
为 ID 字段添加自增函数:alter table 表名 alter column 字段名 set default nextval('函数名');
# 创建函数
happymarket=# create sequence id_increment increment by 1 minvalue 1 no maxvalue start with 1;
CREATE SEQUENCE
# 为ID字段添加自增函数
happymarket=# alter table goods alter column id set default nextval('id_increment');
ALTER TABLE
# 插入数据
happymarket=# insert into goods (title, purchase_price, sell_price, stock, isbn) values
('南方黑芝麻糊',4.5,9.9,10,6901333290660),
('莲花味精',1.8,3.6,10,6901377002007),
('精制沱牌福酒35°',12,24,10,6901435907015);
INSERT 0 3
happymarket=# insert into goods (title, purchase_price, sell_price, stock, isbn) values
('南方黑芝麻糊',4.5,9.9,10,6901333290660),
('莲花味精',1.8,3.6,10,6901377002007),
('精制沱牌福酒35°',12,24,10,6901435907015);
INSERT 0 3
# 查看数据
happymarket=# select * from goods;
title | id | purchase_price | sell_price | stock | isbn | create_time | update_time | unit | spec | brand | supplier | made_in
----------------------------+-----+----------------+------------+-------+---------------+-------------+-------------+------+------+-------+----------+---------
500g万丽厕精 | 1 | 5 | 2 | 10 | 6901121300298 | 2023-01-01 | 2023-01-01 | | | | |
六身除菌香皂(金盏菊)125g | | | 4 | | 6901294171794 | | | | | | |
023-01-02 | 2023-01-02 | | | | |
........太长省略.........
南方黑芝麻糊 | 101 | 5 | 10 | 10 | 6901333290660 | 2023-01-02 | 2023-01-02 | | | | |
莲花味精 | 102 | 2 | 4 | 10 | 6901377002007 | 2023-01-02 | 2023-01-02 | | | | |
精制沱牌福酒35° | 103 | 12 | 24 | 10 | 6901435907015 | 2023-01-02 | 2023-01-02 | | | | |
南方黑芝麻糊 | 201 | 5 | 10 | 10 | 6901333290660 | 2023-01-02 | 2023-01-02 | | | | |
莲花味精 | 202 | 2 | 4 | 10 | 6901377002007 | 2023-01-02 | 2023-01-02 | | | | |
精制沱牌福酒35° | 203 | 12 | 24 | 10 | 6901435907015 | 2023-01-02 | 2023-01-02 | | | | |
(27 rows)
发现,它的执行是出现错误的!id 并没有按照我们预想的进行自增。
这是因为,我们没有设置自增函数的初始值,现在我们将函数的初始值设置为 500
为自增函数设置初始值:select setval('函数名', 500, false);
# 设置自增函数的初始值
happymarket=# select setval('id_increment',500,false);
setval
--------
500
(1 row)
# 看一下表结构
happymarket=# \d+ goods
Orc Table "public.goods"
Column | Type | Modifiers | Storage | Description
----------------+---------------+-------------------------------------------+----------+-------------
title | text | | extended |
id | integer | default nextval('id_increment'::regclass) | plain |
purchase_price | numeric(10,0) | default 0 | main |
sell_price | numeric(10,0) | | main |
stock | integer | | plain |
isbn | text | | extended |
create_time | date | default now() | plain |
update_time | date | default now() | plain |
unit | text | default ''::text | extended |
spec | text | default ''::text | extended |
brand | text | default ''::text | extended |
supplier | text | default ''::text | extended |
made_in | text | default ''::text | extended |
Has OIDs: no
Options: appendonly=true, orientation=orc, compresstype=lz4
Table Bucket Number: 8
Distributed randomly
# 多插入几条数据
happymarket=# insert into goods (title, purchase_price, sell_price, stock, isbn) values
('南方黑芝麻糊',4.5,9.9,10,6901333290660),
('莲花味精',1.8,3.6,10,6901377002007),
('精制沱牌福酒35°',12,24,10,6901435907015);
INSERT 0 3
happymarket=# select * from goods;
title | id | purchase_price | sell_price | stock | isbn | create_time | update_time | unit | spec | brand | supplier | made_in
----------------------------+-----+----------------+------------+-------+---------------+-------------+-------------+------+------+-------+----------+---------
500g万丽厕精 | 1 | 5 | 2 | 10 | 6901121300298 | 2023-01-01 | 2023-01-01 | | | | |
·····················太长省略··································
精制沱牌福酒35° | 203 | 12 | 24 | 10 | 6901435907015 | 2023-01-02 | 2023-01-02 | | | | |
莲花味精 | 501 | 2 | 4 | 10 | 6901377002007 | 2023-01-02 | 2023-01-02 | | | | |
精制沱牌福酒35° | 502 | 12 | 24 | 10 | 6901435907015 | 2023-01-02 | 2023-01-02 | | | | |
南方黑芝麻糊 | 503 | 5 | 10 | 10 | 6901333290660 | 2023-01-02 | 2023-01-02 | | | | |
莲花味精 | 504 | 2 | 4 | 10 | 6901377002007 | 2023-01-02 | 2023-01-02 | | | | |
精制沱牌福酒35° | 505 | 12 | 24 | 10 | 6901435907015 | 2023-01-02 | 2023-01-02 | | | | |
南方黑芝麻糊 | 503 | 5 | 10 | 10 | 6901333290660 | 2023-01-02 | 2023-01-02 | | | | |
莲花味精 | 504 | 2 | 4 | 10 | 6901377002007 | 2023-01-02 | 2023-01-02 | | | | |
精制沱牌福酒35° | 505 | 12 | 24 | 10 | 6901435907015 | 2023-01-02 | 2023-01-02 | | | |
好了,id 现在是自增且有序的了。
另一种方式,是在创建表的时候,有内置的一个类型 SERIAL。
CREATE TABLE 表名(
id SERIAL,
);
总结
同样,对本篇内容中,提到的命令,做一个简单的总结。
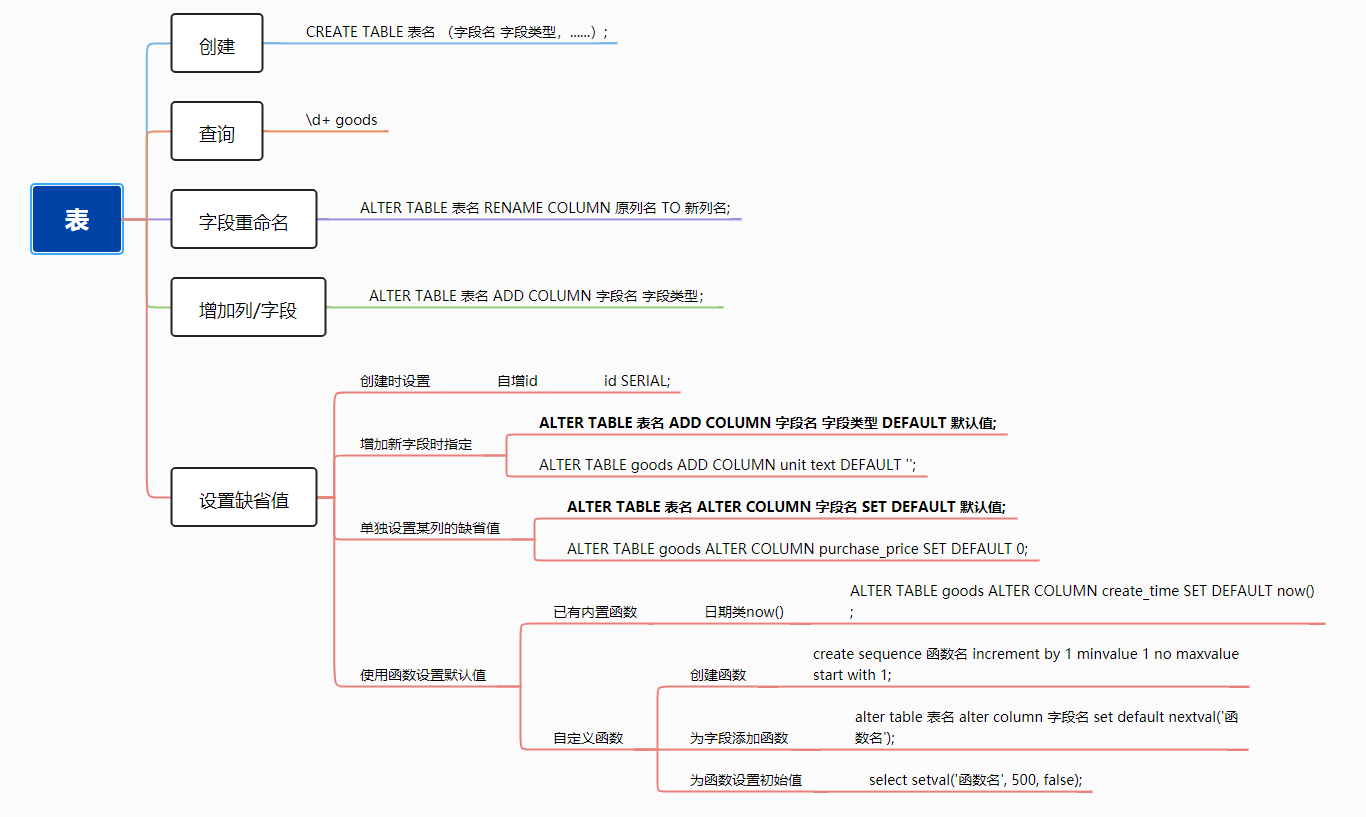
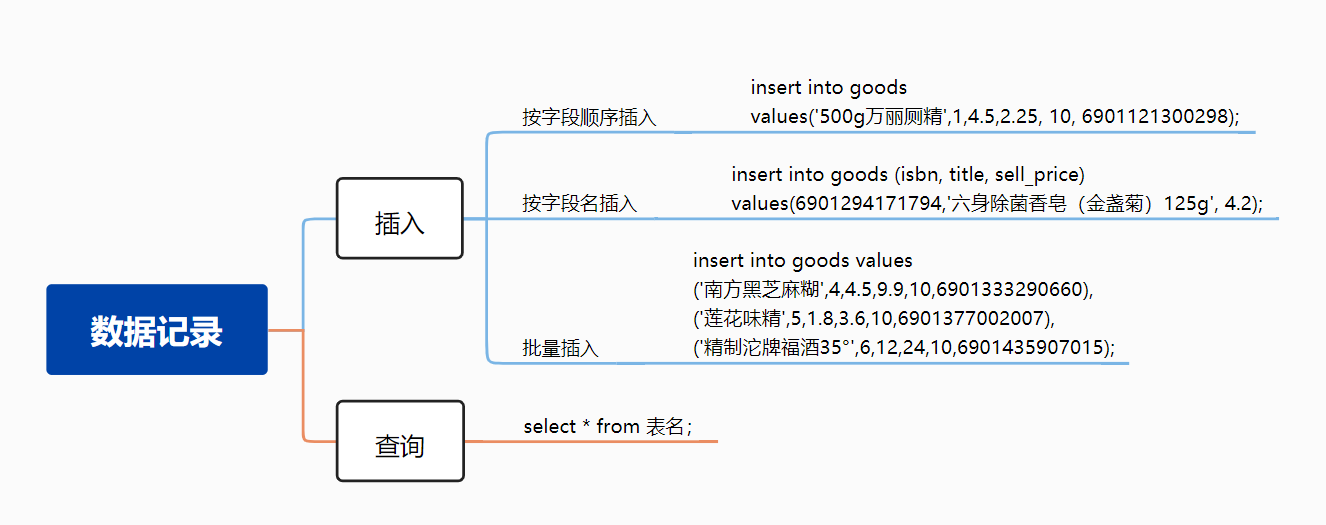
给超市进货时,填充表单的流程,我们大概知道了。下一篇内容,将从技术的角度,探讨、扩展关于数据类型、存储相关的问题:
- 数据类型:为了存储的高效,内置的数据类型有很多,以求适应各种各样的数据。
- 存储方式:为了适应不同的场景,数据的存储分为行存储、列存储,为什么要这么分?有什么意义呢?