【学习贴】偶数的基础架构图
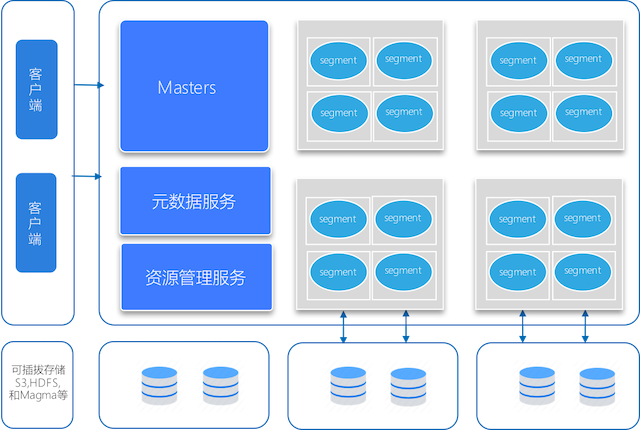
从上图可以看出,偶数数据库的架构设计还是蛮清晰的。
- 从结构上来看,先从左到右看,最左侧的客户端属于应用访问层面,可以理解为客户的容器服务、数据库连接客户端等;
- 再往右是 Master 主节点服务,主节点服务通常只提供外部 SQL 访问和结果数据返回的功能,不存储实质的生产数据,在最新版本的偶数数据库中,Master 节点能提供双节点的访问服务;
- 在 Master 下面是元数据服务和资源管理服务,分别负责元数据的管理和资源的管理,有关资源管理这里理解复用 yarn 提供的功能;在这里有两个问题请教社区的专家:
- 元数据管理从图上看理解为一个单独的服务,请问当前元数据管理从软件设计上,是一个单独的程序吗,还是与 Master 共享同一个程序?
- 在 HDFS 综合环境中,可以用 yarn 来管理服务,那么在单机部署和使用 Magma 引擎时,资源管理是用什么来做呢?
- 再向右是 Segment 节点,Segment 节点是用于数据计算的很多服务实例组成的集群,实例越多,计算能力越强,当然实例过多也会导致分布式计算的消耗越大,并不是越大越好,Segment 节点和最下面这一层的存储服务是强相关的;
- 最后就是最下层的存储服务,可以选择的服务有 HDFS、S3 等或者偶数自研的 Magma 存储引擎,这一部分就是客户最重要的数据资源了,所有的生产数据都存储在这一层。