hdfs问题解决:there are 3 datanode(s) running and no node(s) are excluded in this operation
理解:当我们想向 hdfs 写入数据时,需要由 namenode 提供预期数量的 datanode 进行写入。当 namenode 认为没有足够的 dn 可以使用时,就会出现上边的 error。
造成没有 dn 可用的情况有很多,会陆续更新遇到的情况,下面分析两种遇到的情况。
1,因硬件方面限制导致

对应 nn 日志:
2022-05-10 11:07:52,294 WARN org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy: Failed to place enough replicas, still in need of 1 to reach 2 (unavailableStorages=[], storagePolicy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]}, newBlock=true) [
Node /default-rack/10.20.84.105:50010 [
Storage [DISK]DS-7588f556-3fd7-45d4-8842-4f0fb74267dd:NORMAL:10.20.84.105:50010 is not chosen since the node does not have enough DISK space (required=134217728, scheduled=257698037760, remaining=257820732416).
]
2022-05-10 11:07:52,294 WARN org.apache.hadoop.hdfs.protocol.BlockStoragePolicy: Failed to place enough replicas: expected size is 1 but only 0 storage types can be selected (replication=2, selected=[], unavailable=[DISK], removed=[DISK], policy=BlockStoragePolicy{HOT:7, storageTypes=[DISK], creationFallbacks=[], replicationFallbacks=[ARCHIVE]})
2022-05-10 11:07:52,295 DEBUG org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy: Failed to choose remote rack (location = ~/default-rack), fallback to local rack
日志可以看到是 the node does not have enough DISK space,也就是磁盘空间不足导致的。
在源码中可以找到对应关系。
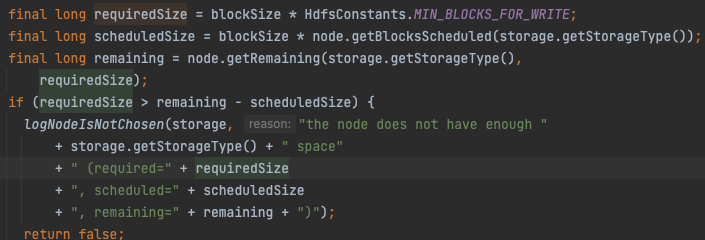
解决:
1,增加 datanode 节点并进行 blance 数据平衡,有足够的空间就不会出现这个问题
2,如果当下不满足增加节点的条件,可以考虑减小 dfs.blocksize 值,使的上面计算公式成立。
2,因 hdfs 集群负载策略导致
在 nn 日志:
2022-04-29 07:15:32,905 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockPlacementPolicy: Not enough replicas was chosen. Reason:{NODE_TOO_BUSY=1}
可以看到 nn 很明确的提示是因为 too—busy 导致 datanode 不能被选中,这里需要注意的是,too_busy 不一定是 hdfs 集群负载过高导致,判断标准为反馈的 dn 所在机器剩余可用资源,也就是说即便当前 dn 没有进行任何任务,但是所在节点因为其他任务导致负载过高,也可能导致这个情况发生,需要整体看。
同样可能会因为 hdfs 负载策略导致没有 dn 被选用的条件如下:
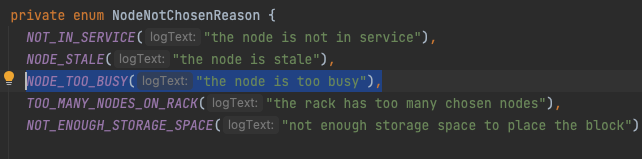
解决:
提示比较明白,根据反馈的对应原因进行调节即可。