hdfs 使用report、fsck检查时 block状态解析
在使用 hdfs 时,经常使用 report、fsck 等基础命令对集群状态、块状态进行检查和修复。而对 block 状态的来源和去向把握,往往可以更好的解决问题。在此记录我在对数据块发生问题进行跟踪过程中了解到的 hdfs block 知识。
如图:report 命令块检查结果
首先明确 数据块的汇报:datanode 通过心跳进行状态维护的同时,也会把各种类型的数据块汇报给 namenode,然后接受 namenode 的反馈处理。
在 namenode 对 blcok 进行处理过程中,会将 block 分为不同类型并进行相应处理。
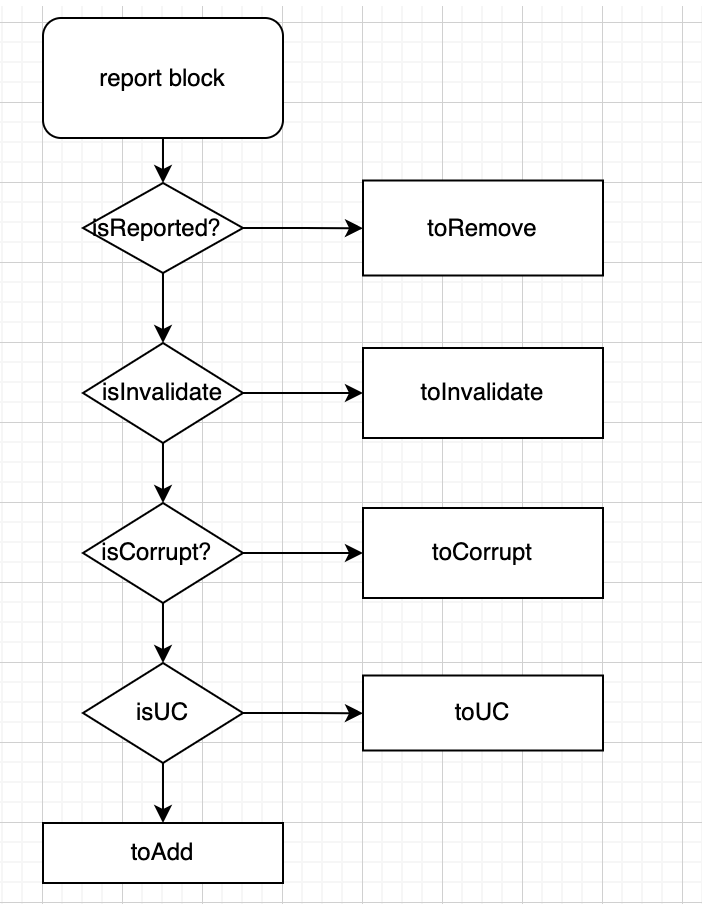
五种 block 类型:
// 新添加块
Collection<BlockInfoToAdd> toAdd = new LinkedList<>();
// 待移除块
Collection<BlockInfo> toRemove = new TreeSet<>();
// 无效快
Collection<Block> toInvalidate = new LinkedList<>();
// 损坏块
Collection<BlockToMarkCorrupt> toCorrupt = new LinkedList<>();
// 正在构建的块
Collection<StatefulBlockInfo> toUC = new LinkedList<>();
1,块汇报
块汇报的方式有两种:
全量汇报:全量汇报只会在进行第一次汇报的时候发生,完成与 namenode 的同步,如果归类,此时所以的块都应该是 toAdd
增量汇报:有变动的块汇报,此时块就拥有了上述五种状态。
可以预见的是,第一次进行全量汇报,因为块的状态一致,可以快速进行批量处理,并不会对 namenode 造成过大的压力。
2,toAdd
新添加块是指新复制完成的块,特征为状态是 finalized。与 toUC 对比看,datanode 并不会在上报的时候明确区分,所以这部分都是由 namenode 处理。没有任何状态的则判定为新增块。
通过 reportDiff 判断新增块,类似与 Git 的 diff。在选出 report 后根据新老块块报告信息的不同,修改维护 block map 中维护的数据关系
3,toRemove
待移除的块,如何理解待移除?
namenode 在判断一个块是否为待移除时,会确认是否在这一流被上报,如果没有上报,则认为 datanode 已经把这个块删除了,然后收集那些没有被上报的块,放在 delimiter 标记块的另一侧,进而通过这个标记块把已经上报的和未上报的块区分开,并将未上报的也就是在 delimiter 标记块的另一侧的数据块放如 toRemove 列表中。
while (it.hasNext()) {
toRemove.add(it.next());
}
for (BlockInfo b : toRemove) {
removeStoredBlock(b, node);
}
public void removeStoredBlock(BlockInfo storedBlock, DatanodeDescriptor node) {
blockLog.debug("BLOCK* removeStoredBlock: {} from {}", storedBlock, node);
assert (namesystem.hasWriteLock());
{
if (storedBlock == null || !blocksMap.removeNode(storedBlock, node)) {
blockLog.debug("BLOCK* removeStoredBlock: {} has already been" +
" removed from node {}", storedBlock, node);
return;
}
可以看到 remove 实际上是把 block 信息从 blocksMap 移除
4,toInvalidate
无效块其实对于 hdfs 来说就是即将执行删除的块。
上文 blocksMap 统计了合法的快信息,换句话说,不在 blocksMap 中的块将被处理,产生的场景:
● 刚刚 toRemove 中在 blocksMap 移除的信息
● 新汇报上来的块中,datanode 有而 namenode 中没有
对于 toRemove 的情况,就是本身准备删除的块。而对于第二种,可以粗略理解为 namenode 中元数据记录丢失回退到之前某一节点,此时 datanode 数据对 nn 来讲就是多余的,会被删除
对于实际删除操作。在 BPServiceActor.offerService 方法会设置一个启动就会持续的循环,wait 心跳设置的时间进行 report 处理,当进入到 toInvalidate 列表,将会在 BlockManager 中调用异步删除由 datanode 响应删除具体的 block 文件。如果想知道具体过程,可以在源码中搜索指定方法查看,这里不赘述。
5,toCorrupt
一般发生于非系统内部的损坏,如人工误删。
case COMMITTED:
if (storedBlock.getGenerationStamp() != reported.getGenerationStamp()) {
final long reportedGS = reported.getGenerationStamp();
return new BlockToMarkCorrupt(new Block(reported), storedBlock, reportedGS,
"block is " + ucState + " and reported genstamp " + reportedGS
+ " does not match genstamp in block map "
+ storedBlock.getGenerationStamp(), Reason.GENSTAMP_MISMATCH);
}
boolean wrongSize;
if (storedBlock.isStriped()) {
assert BlockIdManager.isStripedBlockID(reported.getBlockId());
assert storedBlock.getBlockId() ==
BlockIdManager.convertToStripedID(reported.getBlockId());
BlockInfoStriped stripedBlock = (BlockInfoStriped) storedBlock;
int reportedBlkIdx = BlockIdManager.getBlockIndex(reported);
wrongSize = reported.getNumBytes() != getInternalBlockLength(
stripedBlock.getNumBytes(), stripedBlock.getCellSize(),
stripedBlock.getDataBlockNum(), reportedBlkIdx);
} else {
wrongSize = storedBlock.getNumBytes() != reported.getNumBytes();
}
if (wrongSize) {
return new BlockToMarkCorrupt(new Block(reported), storedBlock,
"block is " + ucState + " and reported length " +
reported.getNumBytes() + " does not match " +
"length in block map " + storedBlock.getNumBytes(),
Reason.SIZE_MISMATCH);
} else {
return null; // not corrupt
}
比较清晰,两个原因会判定为 corrupt:长度不匹配和版本信息不匹配。在此后会加入到 toCorrupt,直到 fsck 的 delete 操作处理。
6,toUC
正在构建中的块,表明块正在进行写操作,判断依据为:
if (isBlockUnderConstruction(storedBlock, ucState, reportedState)) {
toUC.add(new StatefulBlockInfo(storedBlock, new Block(replica),
reportedState));
}
// 对于isBlockUnderConstruction
private boolean isBlockUnderConstruction(BlockInfo storedBlock,
BlockUCState ucState, ReplicaState reportedState) {
switch(reportedState) {
case FINALIZED:
switch(ucState) {
case UNDER_CONSTRUCTION:
case UNDER_RECOVERY:
return true;
default:
return false;
}
case RBW:
case RWR:
return (!storedBlock.isComplete());
case RUR: // should not be reported
case TEMPORARY: // should not be reported
default:
return false;
}
}
逻辑较为清晰,处理比较简单,不过多解释。