偶数支持多样化的存储格式部分内容学习及疑问
参考学习文档为 create table 创建语句的介绍:http://www.oushu.com/docs/ch/SQL.html?highlight=append#create-table
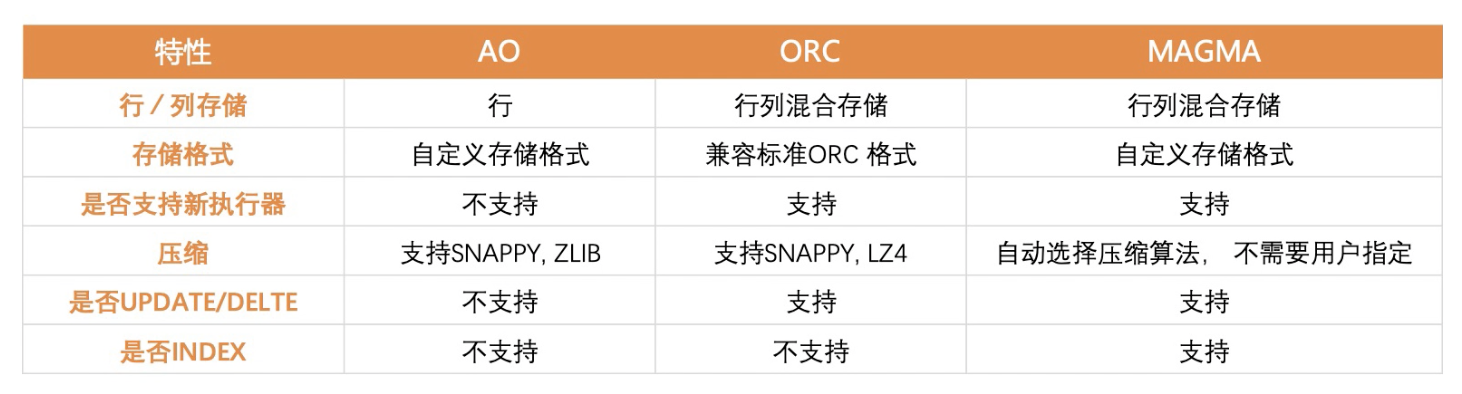
在最近的学习过程中,了解到偶数支持多种存储格式,如上图所示。经过对文档的深度学习,总结如下:
- AO 存储格式 - 这种存储格式全称为 append-only(沿用 gp 早期名称,并有所改进),上图提到 AO 属于行存储格式,从文档中了解到,appendonly=true 时,可以定义三种存储格式:row(default)/parquet/orc,按照理解,row 属于航存储格式,parquet 属于列存储格式,orc 属于行列混存,这里产生一个疑问 1:AO 存储格式这里是不是特指的 appendonly=true,orientation=row ?如果不是,那是否可以说 AO 支持行存或列寸?疑问 2:其实该问题也与上一问题有相关性,文档中提到对 parquet 的支持时,压缩选项描述为 row 支持 zlib 压缩,parquet 提供 snappy 和 gzip 的支持,跟上图也存在部分不匹配问题,这里还请进行说明。疑问 3:在数据库中,默认的行存储方式通常支持索引,为何上图说 ao 不支持 index?这里的数据库 index 是否与我们通常理解的 index 一致?
- ORC 存储格式 - apache orc 是一种优秀的列式存储引擎,能够根据数据类型自己组织索引,具体的介绍可以参考文章。按照通常的理解,我们偶数的 ORC 存储格式是经过优化和改进的,并提供对标准 ORC 格式的兼容,可否介绍一下这里的 ORC 行列混合存储中的行存储是什么概念?另外 ORC 是支持数据自索引的,所以这里说的不支持 index 指的又是什么概念呢?
- MAGMA 存储格式 - 当然重头戏还是 MAGMA 啦,这种格式支持行列混合存储,支持最新的执行器,支持更新和索引,还支持自动选择压缩算法,简直不要太优秀。这里我也抛一个问题:这个自动选择压缩算法是如何处理的?依据数据类型的嘛?
以上内容是我对偶数数据库支持的多样化存储格式的学习心得及疑问,还请各位专家不吝赐教,orz。另外上图是否可以增加一个最佳使用场景建议呢?