LittleBoy最佳实践样例:在画布中使用已训练好的模型对数据进行预测评估
上节我们讲到了如何在 LittleBoy 可视化机器学习建模平台画布中进行模型训练和预测评估,而模型完成之后会自动持久化保存到平台中,供我们后期做模型调用、模型比较、模型版本迭代等操作。下面来简单演示一下如何在画布中调用已训练好的模型对数据进行预测和评估。
1.本次调用的模型为上节训练好的多分类模型,使用该模型对 iris_test 数据集进行预测
下图为模型详情和数据集预览

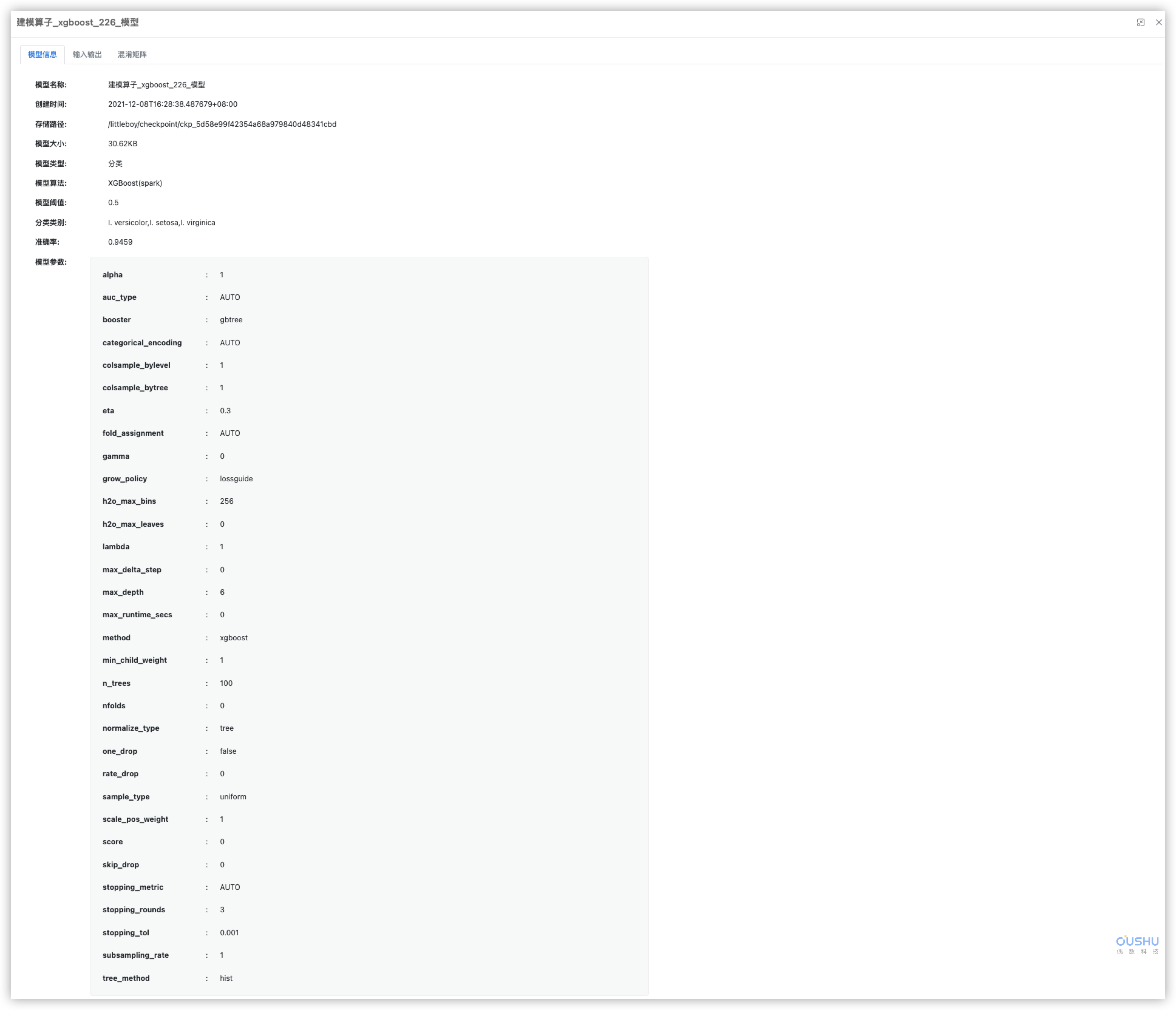
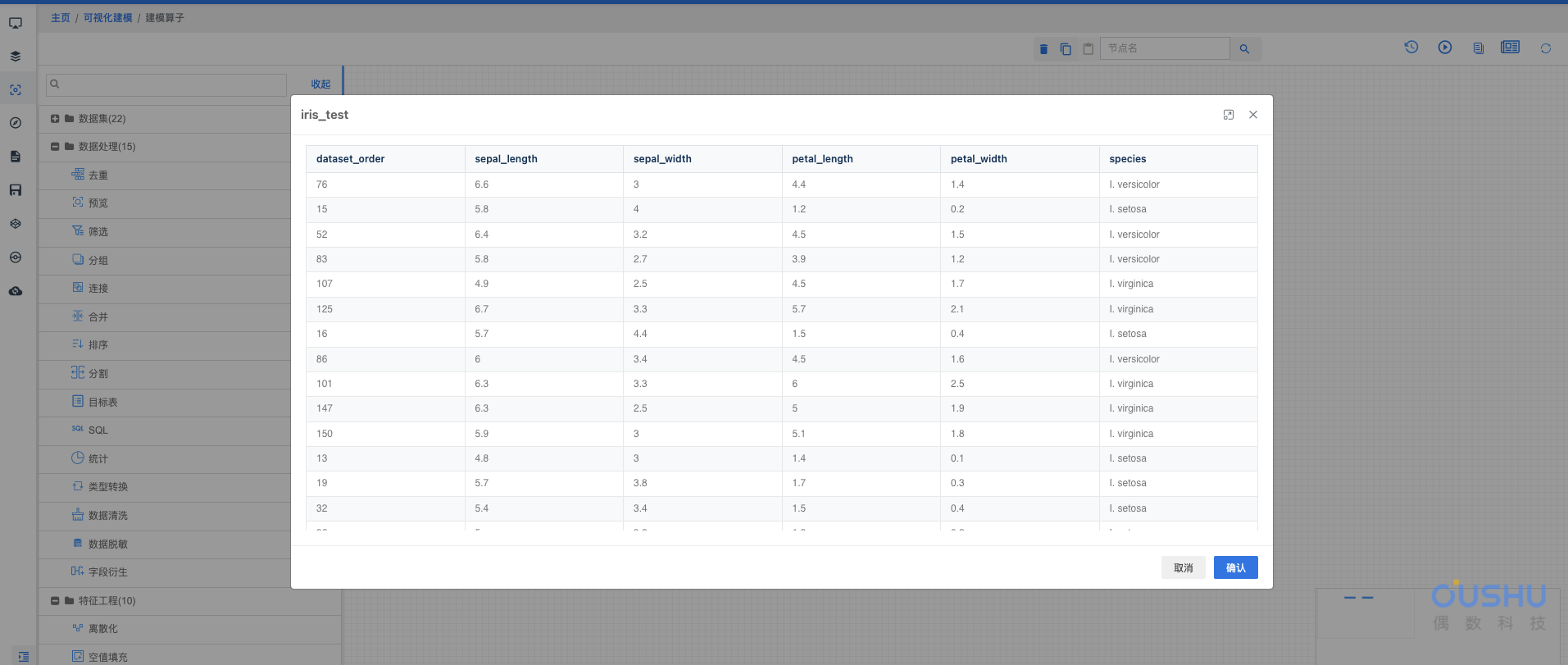
1.1 从机器学习模块下拖动预测算子连接模型和数据集,连接之后打开预测算子进行配置,模型中有记录特征字段,会自动匹配进行预测

1.2 预测算子之后接入多分类评估算子,对预测结果进行评估,验证模型效果

1.3 整体流程如图所示,点击运行画布

1.4 如图,画布已运行完成,接下来我们就可以查看运行结果

1.5 点击预览算子即可查看模型对 iris_test 数据集的预测结果

1.6 点击多分类评估算子,查看对测试数据集预测结果的评估值



以上就是在 LittleBoy 可视化机器学习建模平台画布中使用已训练好的模型对数据进行预测评估的流程。