4.13. HDFS namenode全部挂掉,重启后oushudb查询个别表报错
➢ 现象
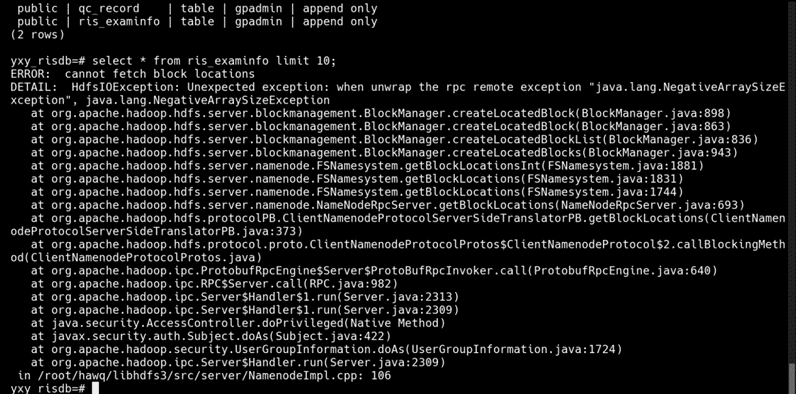
➢ 分析
HDFS bug, Fix Version/s: 2.9.0, 2.7.4, 3.0.0-alpha4, 2.8.2
HDFS 出错 code
final int numCorruptNodes = countNodes(blk).corruptReplicas();
final int numCorruptReplicas = corruptReplicas.numCorruptReplicas(blk);
if (numCorruptNodes != numCorruptReplicas) {
LOG.warn("Inconsistent number of corrupt replicas for "
+ blk + " blockMap has " + numCorruptNodes
+ " but corrupt replicas map has " + numCorruptReplicas);
}
final int numNodes = blocksMap.numNodes(blk);
final boolean isCorrupt = numCorruptReplicas == numNodes;
final int numMachines = isCorrupt ? numNodes: numNodes - numCorruptReplicas;
DatanodeStorageInfo[] machines = new DatanodeStorageInfo[numMachines]; // numMachines 为负,抛出异常!!!
Datanode shutdown,由于 bug 的存在,导致 namenode 持有的两个关于 block 信息的数据结构不一致,接着根据这两个数据结构大小之差创建数组,因为大小之差为负,所以抛出 NegativeArraySize 异常。
jira 里面是这么说的:
Looks like the root cause for this inconsistency is: BlockInfo#setGenerationStampAndVerifyReplicas may remove a datanode storage from the block's storage list, but still leave the storage in the CorruptReplicasMap.
This inconsistency later can be fixed automatically, e.g., by a full block report. But maybe we should consider using BlockManager#removeStoredBlock(BlockInfo, DatanodeDescriptor) to remove all the records related to the block-dn pair.
更多详情见 jira:https://issues.apache.org/jira/browse/HDFS-11445
提及同样问题的 jira:https://issues.apache.org/jira/browse/HDFS-12676
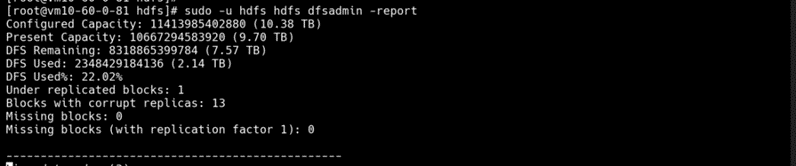
➢ 解答
此类「can not fetch block」问题,通常使用 hdfs dfsadmin -triggerBlockReport 做一次 full report,就会自动恢复。
问题更加详细的信息可以查看 issue:
https://github.com/oushu-io/support/issues/411