1. 背景介绍
4 月 6 号的时候,客户的数据库出现了异常,初始的报错如下:

客户的环境配置:双 magma 节点,replica=2,数据库版本 4.9。
得到报错后,初步怀疑 magma 集群出了问题,因为事务系统和容错系统均在 magma 服务中。
2. 排查过程
作出初步怀疑后,得到了如下后续调查日志
magma 集群状态:
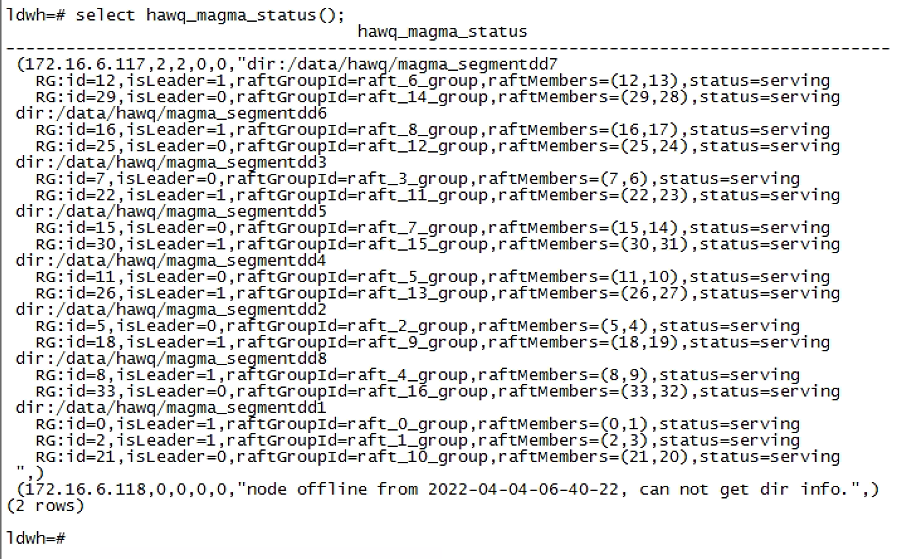
qd 日志:
magmafatal 日志:
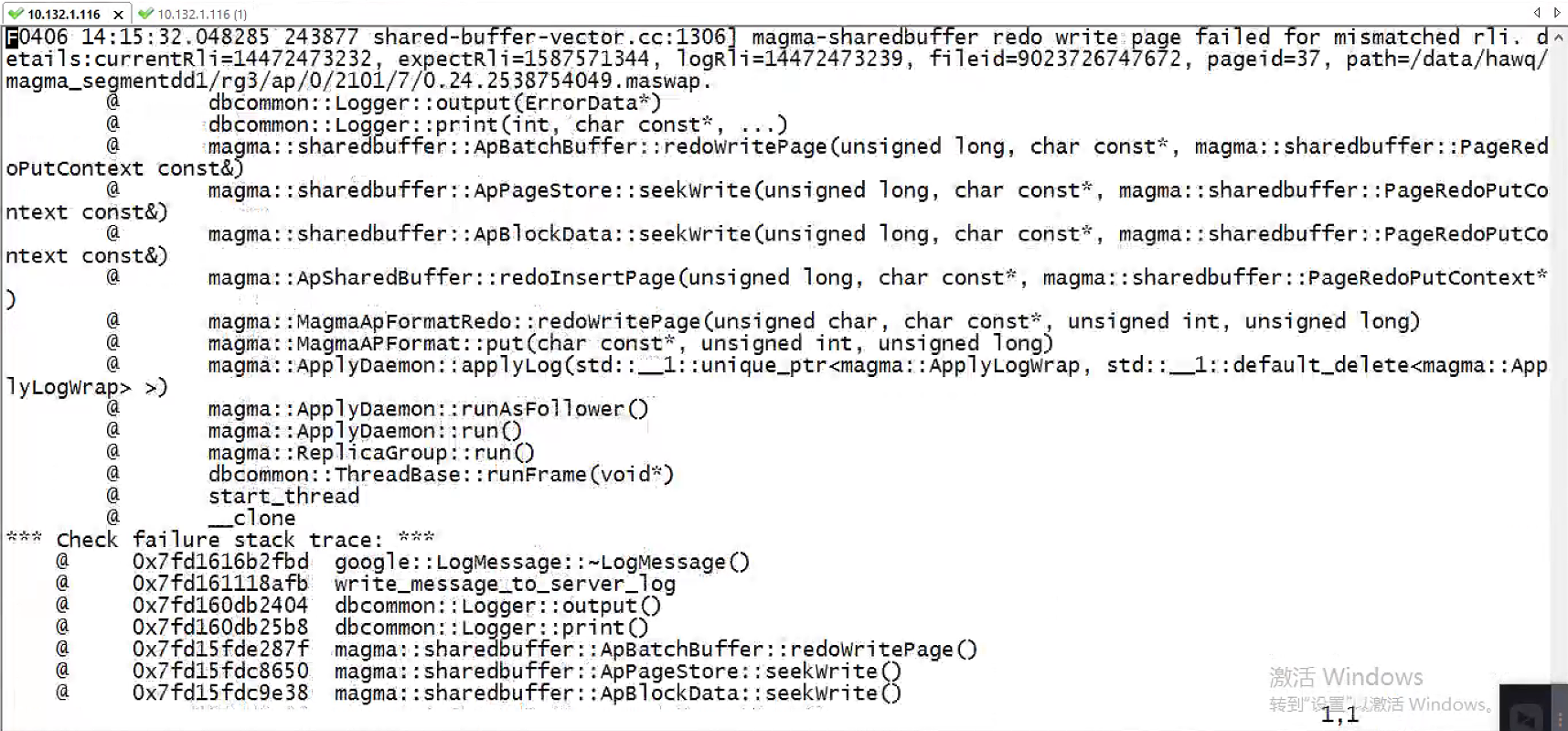
可以确认的是:magma 有一个 node 无法启动,导致在去请求 snapshot 的时候报错,而 fatal 则指出了错误根源:magma fallowernode 在重启后对 raft log 做 redo 的时候遇到了问题:在 redo 校验时遇到了一个意外的很小的 expectrli 日志,校验失败,而无法成功重启。
3. redo 过程中的 rli 日志指的是什么?
rli 指的是 raft log index,用来标识存储的历史事务操作行为。在 magma raft 中,leader 会向 fallower 同步日志,而同步过程中,会利用 raft log index 来比对自己的文件历史是否与 leader 一致,如果始终不一致,节点会认为数据不同步,最终退出。
4. debug
在遇到这个问题后,我们能够明确的是:预期的 expectrli 是一定是大于或者等于当前 rli 的。而 node 得到了一个在数量级上都小于当前 rli 的同步标志。当前 rli 日志的数量级大于 2^32,而预期的 rli 日志至少比当前 rli 大,但是我们却得到了一个与 2^32 一致的数量级数字,我们怀疑在某个位置的 rli 数据被截断了。猜想是 64 位的标志截断为了 32 位数据。在同事的帮助下,通过排查代码终于发现某个函数计算的返回值类型错误,该错误导致了 rli 无法落盘为大于 32 位的值,并最终导致了服务宕机。
得知问题原因后,第一时间将该 bug 恢复。由于该数据落盘存储后并非直接可读,并且修改落盘数据比较困难,无法确定对其他数据的影响,最终我们计划在数据库 magma 启动时通过调试手段将 magma 存储拉起。
5. 事先准备
不像一般的 debug 行为,我们接触的操作环境是客户的生产环境,软件也以 release 版本安装,客户环境不仅仅是当时的系统环境,还包括数据库的内部运行环境都可能与我们预期的差异巨大。因此为了防止在客户环境上出现任何预料之外的场景,事先模拟是十分必要的。
这里的事先模拟包括:
- bug 切实复现
- 运行状态恢复切实可行
- 若服务未拉起能够恢复如初
- 状态恢复后验证
我认为在复现工作中一定要注意的是:软件版本一定要对应,结果一定要一致,环境也要尽可能相似。
我们的调试恢复计划是在 magma 进程启动后在做 redo 检查时,使用 lldb 断点打到执行对比之前,修改值使之跳过比对,结合代码判断后续的行为是否需要继续干涉,在 magma 服务成功拉起后,数据库做 checkpoint,使用正确的 rli 值覆盖历史上错误的值,消除错误。
6. 入场恢复
入场后第一步操作:备份,保留可恢复的现场。这里只有一张涉事表,保险起见,我们将整个 rg 做了备份,这里是 rg2 和 rg3。
实际上,尽管有事先模拟,但是仍有一些场景我们并未提前注意到:使用调试工具打断点的时机以及修改的时间窗口(还要注意的是,我们经常使用远程工具,可能跳了好多次,在客户环境下的操作十分有限)。尤其是数据库本身服务中有大量的定时任务,有些定时任务依赖的关键信号被暂停或终止后可能会将整体服务引入一个错误的状态。基于 raft 大量集群的同步选举规则,2 节点的集群恢复工作要简单于更多节点的恢复工作,在更大规模集群的恢复过程必定困难重重。
在实际恢复过程中,在打断点时一定要迅速且尽量一致的中断程序,并且考虑将相关的程序都打断点,遇到断点后一定要迅速的修改参数值,防止意外的状态切换。
经过多次尝试后,我们成功将程序中断在预想的位置。
在选择中断点时,中断点考虑向前一些,以防有些程序优化使我们错过机会。并且需要注意:一些程序优化可能将参数的值提前放到了寄存器中,导致你的修改无法影响程序执行,这时候可以在靠前的位置或者上一层调用中修改条件值。
经过多次尝试,并跟踪程序运行到我们无需修改的状态后,我们如愿拉起了 magma 服务。拉起服务后启动 oushudb,做一些 SQL 并 checkpoint,完成错误 rli 的覆盖。
后续便是监测一段时间,确认服务的确拉起。
7. 总结
这次恢复工作花了一些时间,在客户环境上做了很多测试与修改。也留下一些经验教训:
- 落盘持久化的数据一定慎之又慎,因为一旦落盘错误,错误的数据就再也恢复不了了,幸运的是这次可以想办法跳过,并且这部分数据和用户数据关系不大,有机会拉起来。
- 进入客户环境在程序里做修改操作一定要提前模拟,要本地复现,并能够真正拉起来,后续检测正常。
- 做好备份,确认操作是可以重复进行的(至少恢复到之前的错误状态)!如果操作机会仅有一次,错误的修改或者时机不当将引发灾难。
- 客户环境 lldb 时,断点尽可能向前打,修改确认生效,能够得到预期的反馈,跟踪后续的执行无误,并注意时间窗口(手速要快)!
另外,感谢在客户问题恢复过程中同事们的帮助与支持/抱拳